For most of us who learned CNN, we already knew the convolutional operation is used for feature extraction in the spatial relationship. Compared with the full connection NN, it is good for weights sharing and translation invariant. There are many different convolutions. Recently, I found a very good article which summarized this topic. I translated it to English combined with my understanding. If you want to read the original one, you can go here.
1. Standard Convolution
1.1 Single channel
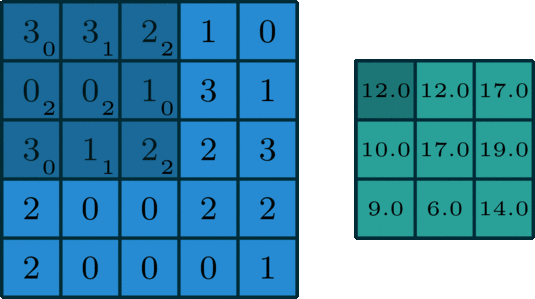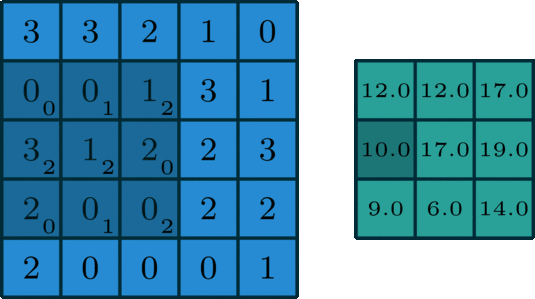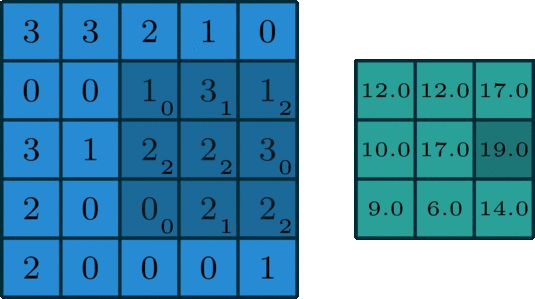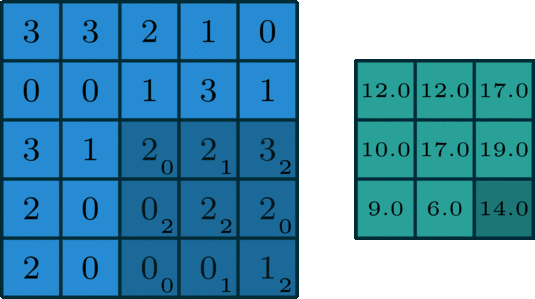
It’s element-wise multiply then sum together. The Convolutional filter moves forward each element in the picture. Here we set padding = 0, stride = 1. This is very useful for the gray picture.
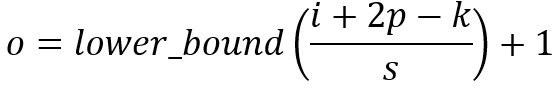
1.2 multi channels
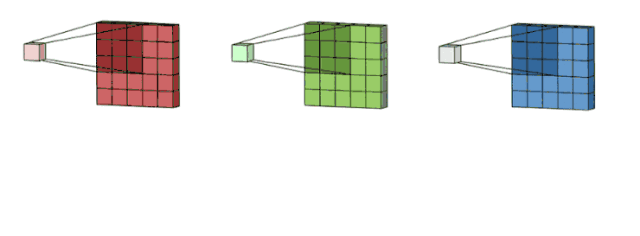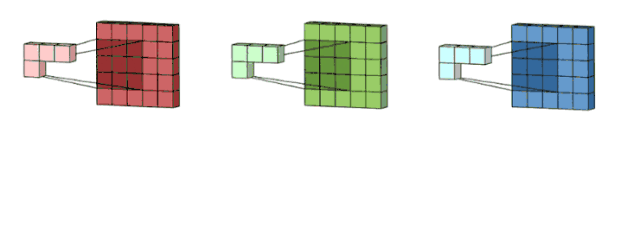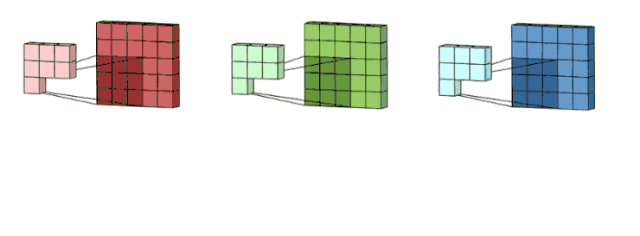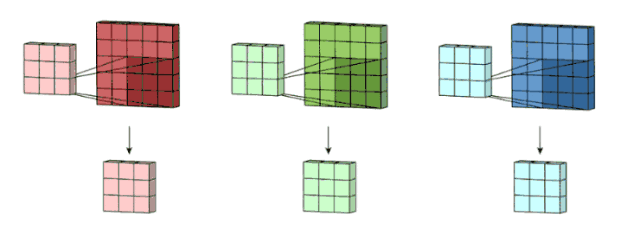
For the color pictures, they are made of 3 layers: Red, Green and Yellow. we create a 333 convolution which contains 3 convolutional kernels. Then we sum the three results togher to one channel 2D array.
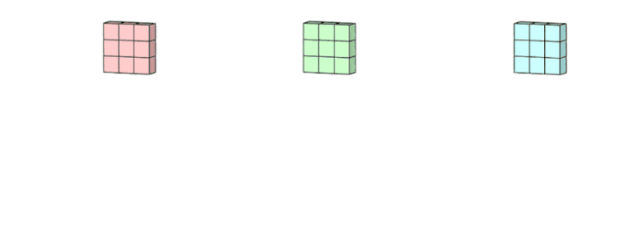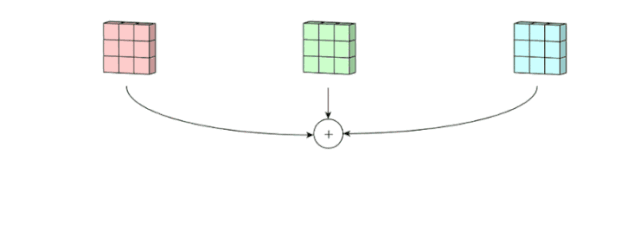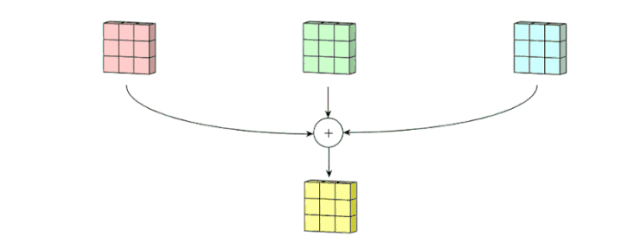
Although we have 3D convolution filter, it is still 2D opertion since we just move the filter in 2D ways(height and width).
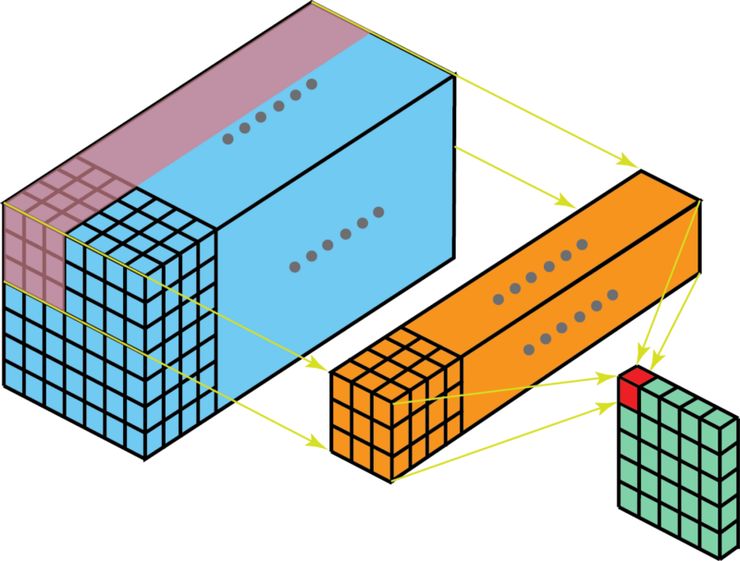
Here is the tricky part. If we add multiple 3D convolution filter(depth = channel), we can get multiple channels output as well.
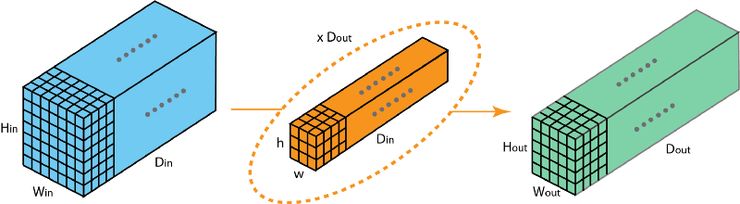
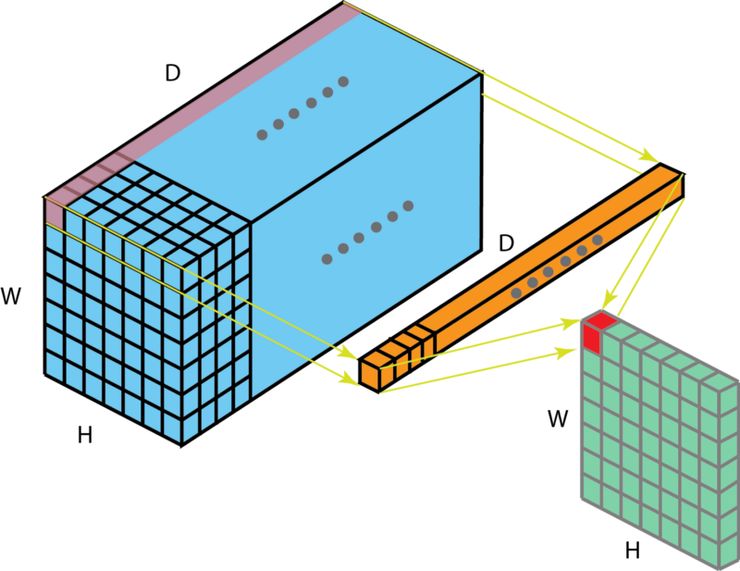
Here we can find the input depth = Din, out filter is hwDin, the total filter number is Dout, after convolutional operations, we get HoutWoutDout output.
2. 3D Convolution
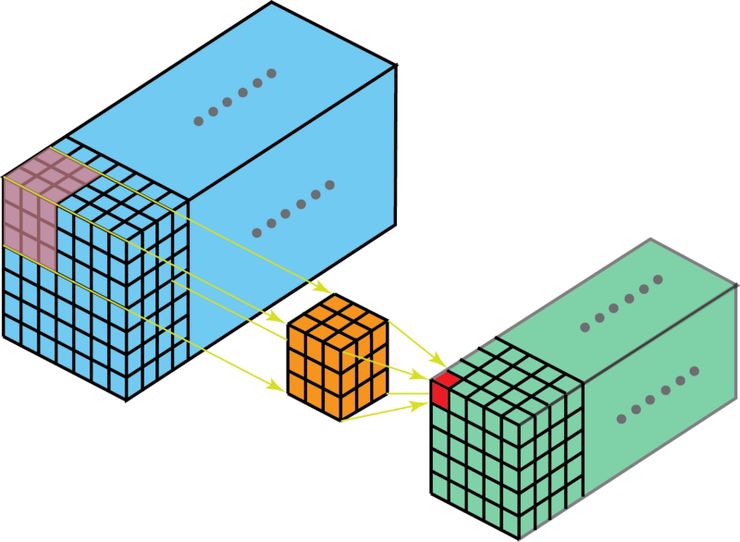
If the depth of filter less than depth of input, the filter can move with 3D ways. So that our output is a 3D output as well. If we need to find spatial relationship in 3D, like CT or MRI in the medical area.
3. 1*1 Convolution
11 convolution is very interesting one. Although it can not find the spatial relationship, it really helpful to: A. reduce dimension B. introduce nonlinear features. As Yann LeCun said, the 11 convolutional filter can replace fully connection layer.
4. Deconvolution
In same case, we need to up-sampling or mapping to high dimension from low dimension. Traditionally, people use interpolaton to achieve this operation to get high resolution pictures, but deep learning can automatically to learning the information through huge samples.
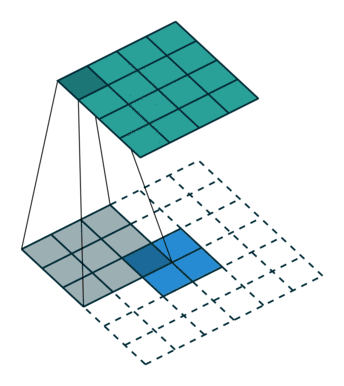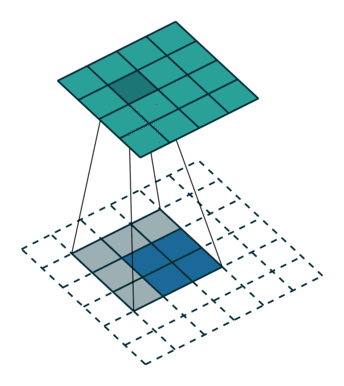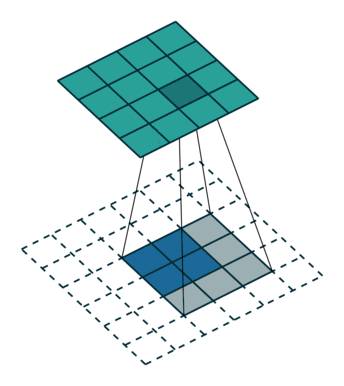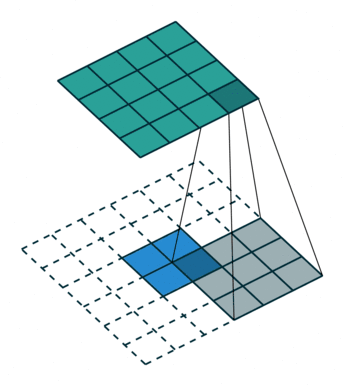
We use convolution to achieve deconvolution where the input is 22 and output is 44.
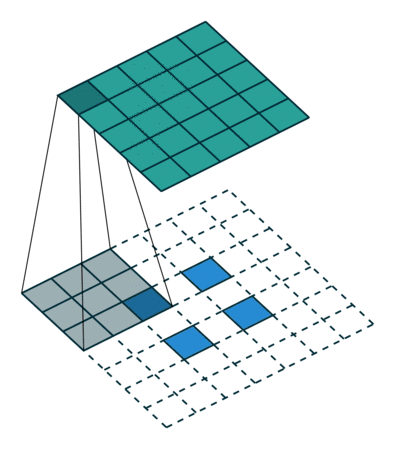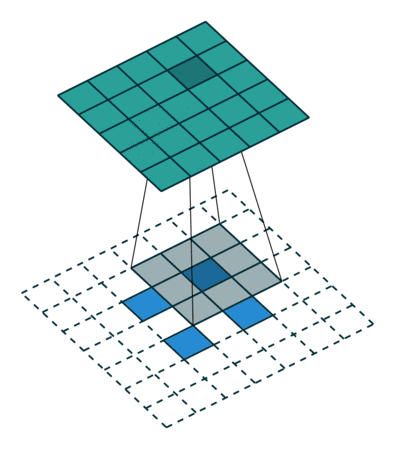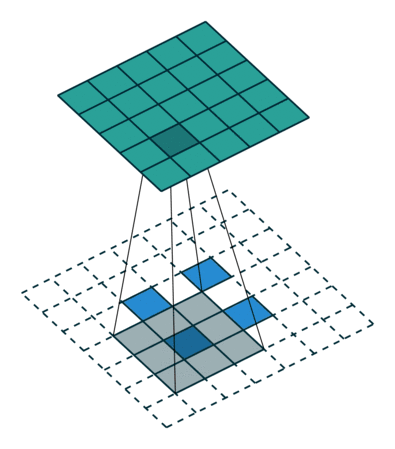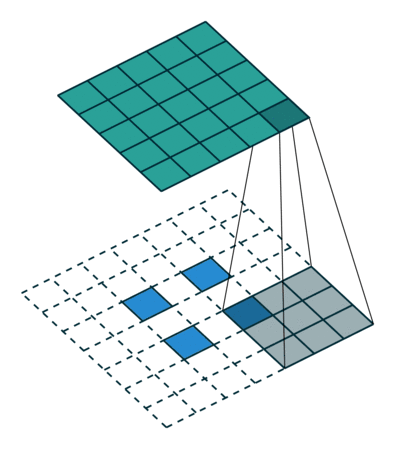
The interesting part is we can use empty element to fill the block between input elements and change the stride and padding as well.
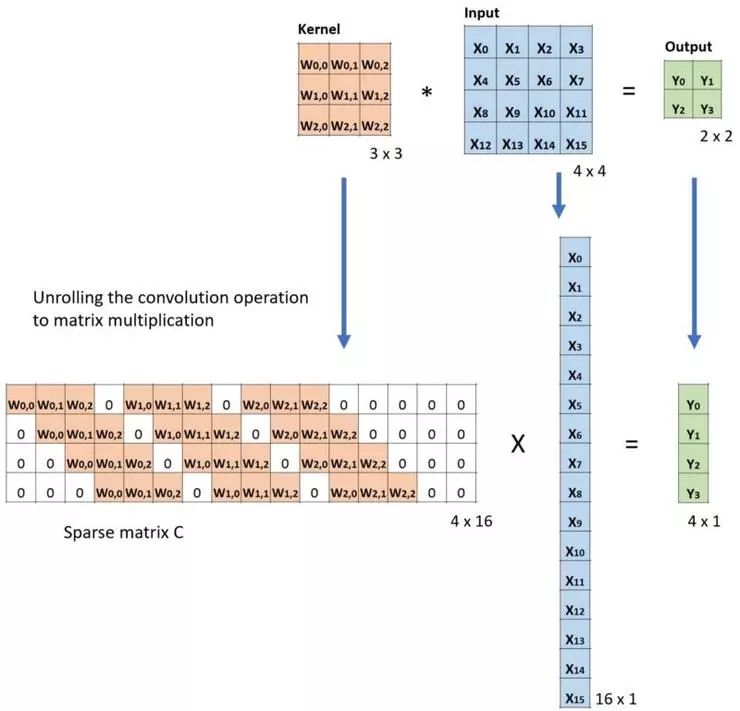
This is a sample we do the down-sampling(convolution). Here we translate the kernel to a sparse matrix, and input to a flat array.
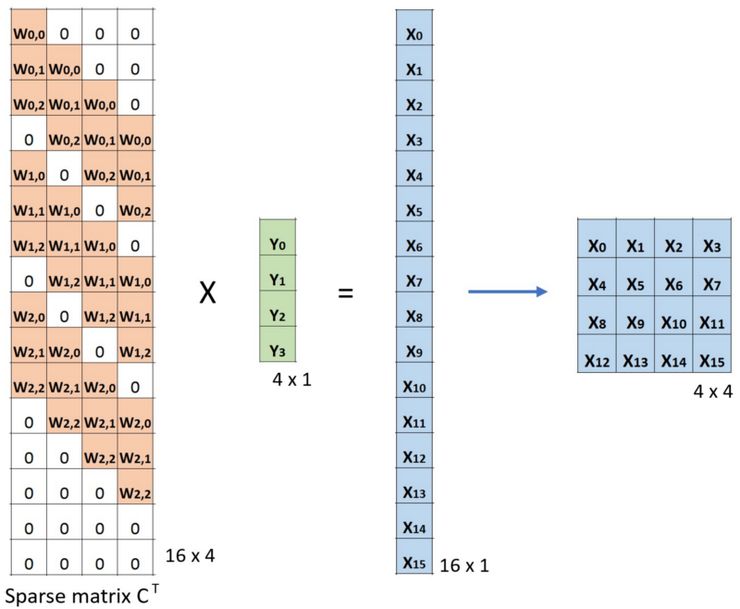
So that up-sampling(Deconvolution) is to find proper sparse matrix to get a high dimensional matrix.

In the processing of up sampling, we might meet checkerboard artifacts since unevenoverlap.
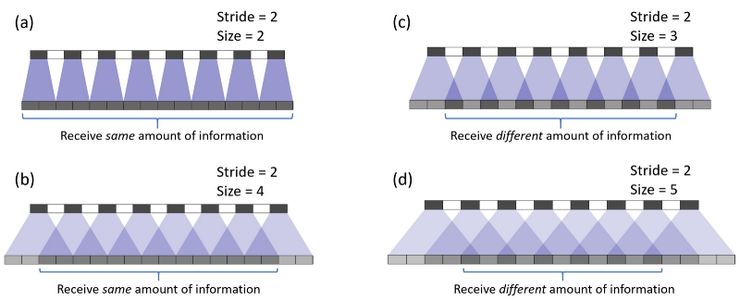
Ueven overlap is due to the elements of outputs receive different amount of information. If we look at the picture above, we can find in (a),(b), all most every elements of output can get same amount of infomation, but in (c),(d) they are not. We can try to make filter size is dividable to stride to reduce checkerboard artifacts.
5. Dilated Convolution
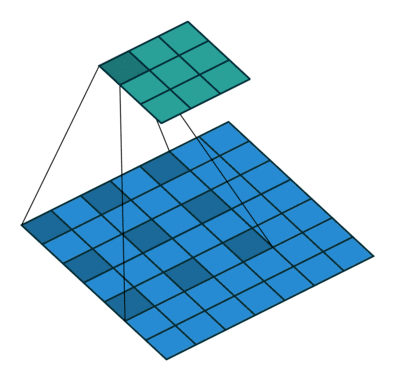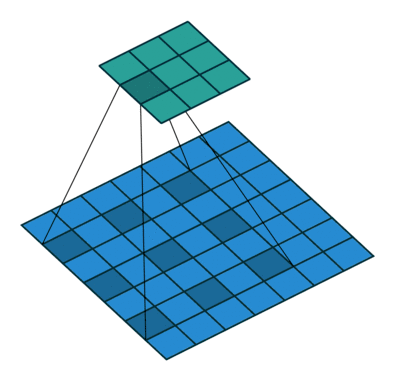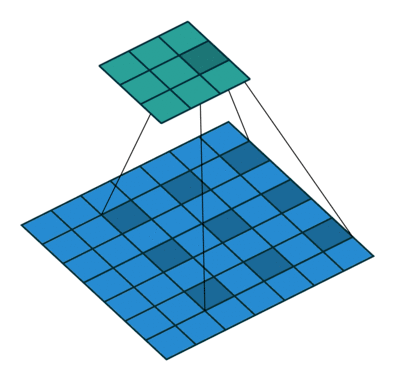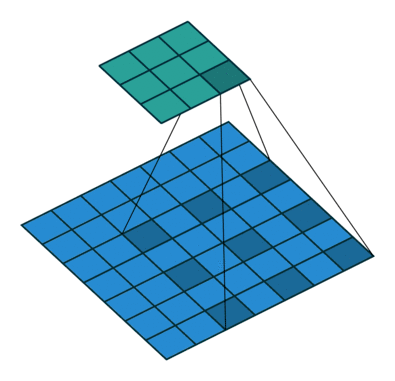
Dilated Convolution adds space between kernel which leads to a bigger receptive field with same amount of kernel size in the standard convolution.
6. spatially separable convolution
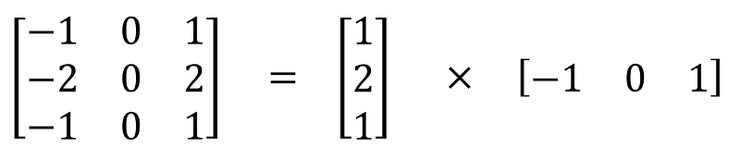
We already know a matrix can be split into a product of two matrix. In the same way, we can split the convolution to two arrays.
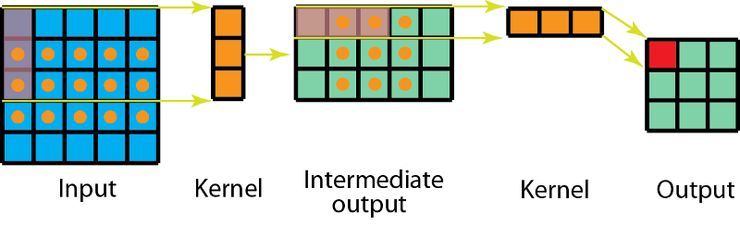
This process can signifantly reduce the computational cost, but the problem is not all convolution can be split.
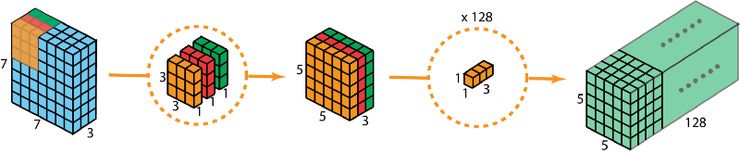
Depth-wise separable convolution utilizes the same way to reduce cost. First, it uses three 331 kernel to handle three channels. The outputs is three channel as well. Second, use N 113 kernals to get output with depth = N. The advantage is fast, the cost much less than 2D convolution. But the problem is reducing the amount of params which reduce the model ability as well.
6. Flattened convolution
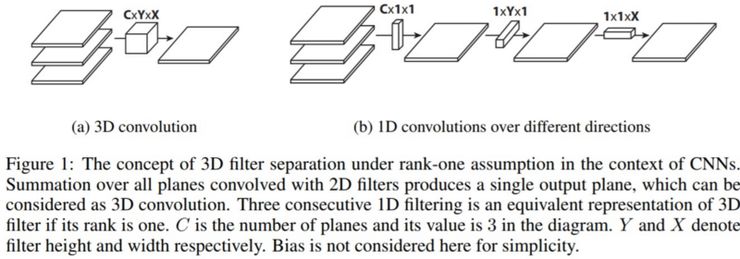
Flattened convolution splits standard filter into 3 1D kernels.
7. Grouped convolution
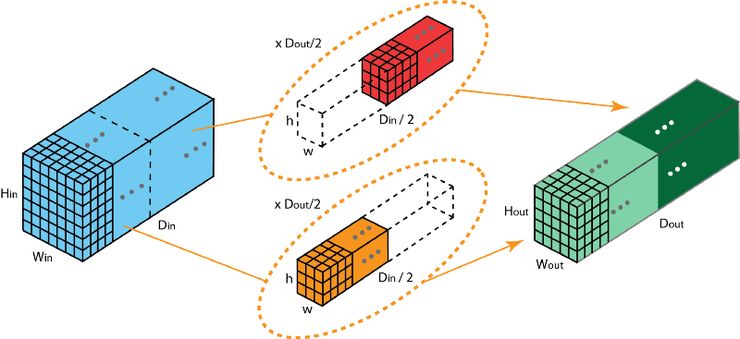
If we have mutiable GPU/TPU, we can parallelly running our model. Just split the tasks by one dimension. Grouped convolution is fast in training, less params and better results.
8. Shuffle convolution
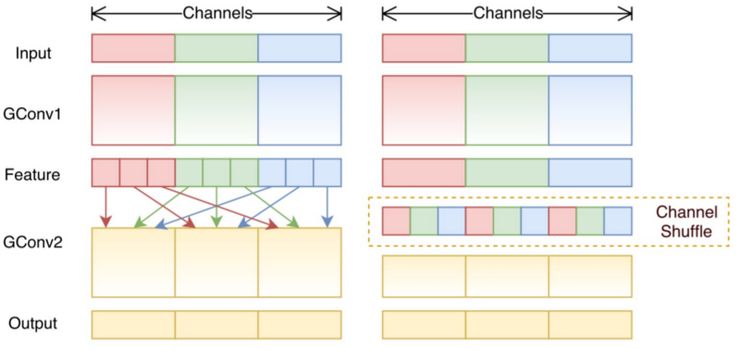
If we use 3 filter to handle 3 channels, the problem is missing information crossing channel. In shuffle convolution, it adds a shuffle process to mix information between channels.
Leave a Reply