Recently I was given a topic to research a manner to summary the text automatically. So I shared some my search results, hope it is helpful.
Summarization Methods
we can classify summarization methods into different types by input type, the purpose and output type. Typically, extractive and abstractive are the most common ways.
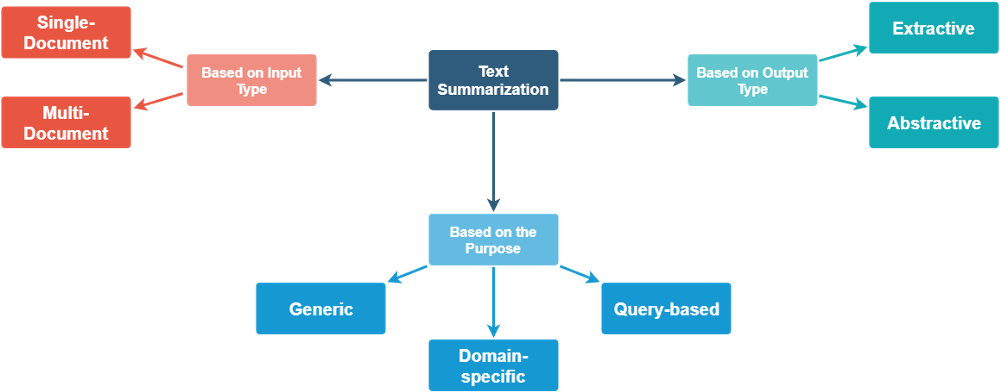
Here, we would like introduce two methods for Extractive. One is Stats-based , another is Deep Learning-based.
Stats-based
- Idea: for each word, we would give a weight frequency. For each sentence, we summary the weight frequency for the words inside. Then pick up the sentences ordered by the sum of weight frequency.
- Steps
2.1 Preprocessing: replace extra whitespace characters or delete some parts we do not need to analysis.
replace = {
ord('\f') : ' ',
ord('\t') : ' ',
ord('\n') : ' ',
ord('\r') : None
}
data.translate(replace)
2.2 Tokenizing the sentence
sent_list = nltk.sent_tokenize(content)
2.3 Get frequency of each word
stopwords = nltk.corpus.stopwords.words('english')
word_frequencies = {}
for word in nltk.word_tokenize(formatted_article_text):
if word not in stopwords: if word not in word_frequencies.keys():
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
2.4 Weighted frequency of occurrence
maximum_frequncy = max(word_frequencies.values())
for word in word_frequencies.keys():
word_frequencies[word] = (word_frequencies[word]/maximum_frequncy)
2.5 Calculate the sum of weight frequency for each sentence
sentence_scores = {}
for sent in sentence_list:
for word in nltk.word_tokenize(sent.lower()):
if word in word_frequencies.keys():
if len(sent.split(' ')) < 30:
if sent not in sentence_scores.keys():
sentence_scores[sent] = word_frequencies[word]
else:
sentence_scores[sent] += word_frequencies[word]
2.6 sort sentences in descending order of sum
import heapq
summary_sentences = heapq.nlargest(7, sentence_scores, key=sentence_scores.get)
summary = ' '.join(summary_sentences)
print(summary)
Deep Learning-based
- Idea: vectorizing each sentence into a high dimension space, then cluster the vector using kmean, pick up the sentences which mostly close to the center of each cluster to form the summery of text.
- steps:
2.1 prepossessing and tokenizing the sentence( same asstats-basedmethod)
2.2 Skip-Thought Encoder
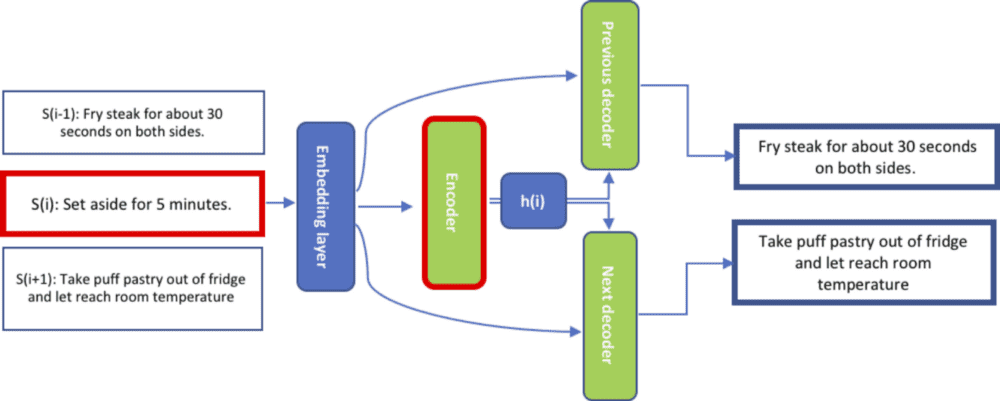
Encoder Network: The encoder is typically a GRU-RNN which generates a fixed length vector representation h(i) for each sentence S(i) in the input.
Decoder Network: The decoder network takes this vector representation h(i) as input and tries to generate two sentences — S(i-1) and S(i+1), which could occur before and after the input sentence respectively.
These learned representations h(i) are such that embeddings of semantically similar sentences are closer to each other in vector space, and therefore are suitable for clustering.
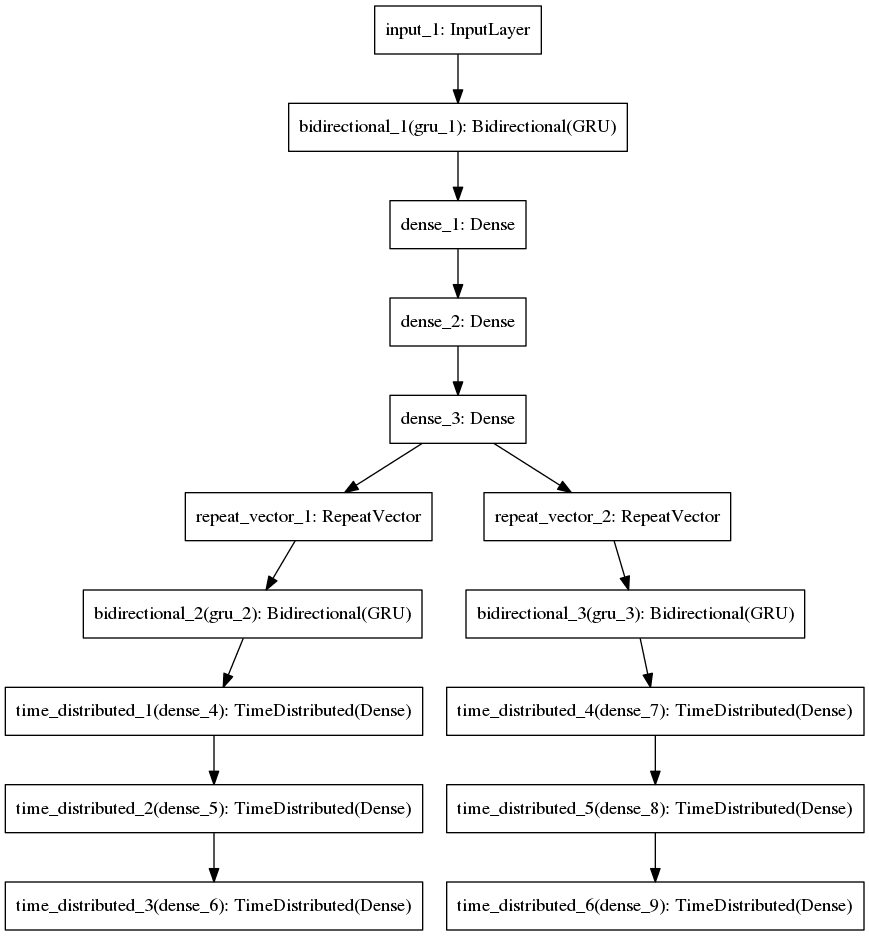
Skip-Thoughts Architecture
import skipthoughts
# You would need to download pre-trained models first
model = skipthoughts.load_model()
encoder = skipthoughts.Encoder(model)
encoded = encoder.encode(sentences)
2.3 Clustering
import numpy as np
from sklearn.cluster import KMeans
n_clusters = np.ceil(len(encoded)**0.5)
kmeans = KMeans(n_clusters=n_clusters)
kmeans = kmeans.fit(encoded)
2.4 Summerization
from sklearn.metrics import pairwise_distances_argmin_min
avg = []
for j in range(n_clusters):
idx = np.where(kmeans.labels_ == j)[0]
avg.append(np.mean(idx))
closest, _ = pairwise_distances_argmin_min(kmeans.cluster_centers_, encoded)
ordering = sorted(range(n_clusters), key=lambda k: avg[k])
summary = ' '.join([email[closest[idx]] for idx in ordering])
Reference:
- Unsupervised Text Summarization using Sentence Embeddings,https://medium.com/jatana/unsupervised-text-summarization-using-sentence-embeddings-adb15ce83db1
- Skip-Thought Vectors, https://arxiv.org/abs/1506.06726
- Text Summarization with NLTK in Python, https://stackabuse.com/text-summarization-with-nltk-in-python/
Leave a Reply