Since version 2019.3, Tableau starts to support databricks with the native connection driver. So we don’t have to use some wired unknown product or custom API to connect them together. Here is the step how to use it simply.
- Download the new version of Tableau through pre-release page. (it will come to the official version soon)
- Download the supported Simba ODBC driver. and install it.
- After all these two steps, you will find Databrick option in your tableau connect.

The next steps are figuring out the authorization information for databricks.
- Login Databricks.
- Go to Cluster – <your selection cluster name> – Advanced Options – JDBC/ODBC
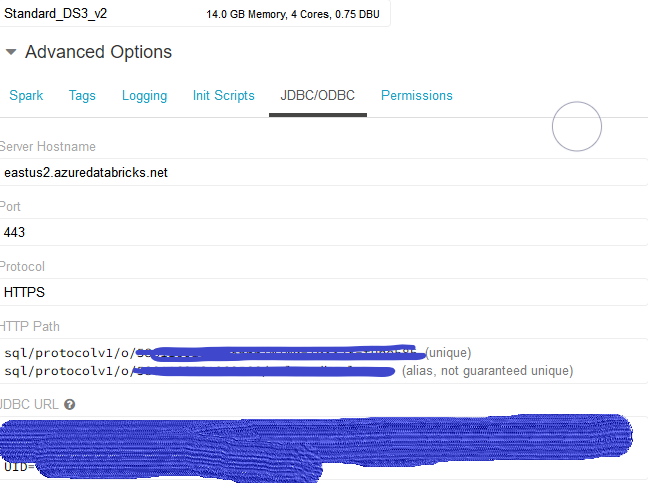
Here you can find Server Hostname and Http path, copy them to authorization page.
For user name and password, you have to use token.
- find the little logo on the right up corner. Press it then choose user setting.
- Click “Generate new Token”. there will be a popup windows, save the series code which is your PASSWORD.
- Enter “token” as username, the code you just got as the password. Then you can see the tables you created in databricks.
For Saving tables in databricks, it is also simple.
df_test = spark.read.format("parquet").load("/mnt/aclaradls01/test/dcu_health.parquet")
df_test.write.mode('overwrite').saveAsTable("df_test") Tips:
We can also use spark SQL to connect databricks. And even use databricks as API to connect to datalakes. It pretty much like a cluster running Spark. Here is the steps:
- create a view in databricks which links to the mounted datalake path. spark.sql(“create view df_test_view as SELECT * FROM parquet.
/mnt/<mounted_name>/<folder_name>/“) - Add “spark.hadoop.hive.server2.enable.doAs false” into your cluster spark config.
- If you tried to load large size data which takes long time, add spark.executor.heartbeatInterval 10s and spark.network.timeout 9999s to your cluster spark config as well.
Reference:
Tableau with databricks. https://docs.databricks.com/user-guide/bi/tableau.html
Leave a Reply