It is harder and harder to write down a long journal focusing on a single topic since most of the time is spent burning my fat these days. Maybe it is time to list some problems we solved or still listed after half a year without updating.
Issue 1. Too many job clusters launched in pipelines.

One year ago, we implemented Bronze, Silver, Gold structure with delta tables. It was very convenient to process big data with correct partitions. However, there are some issues in our pipelines:
- Too many resources are needed and cluster launch time is also wasted. The screenshot above shows 3 clusters requested. And there is a loop outside of these 3 clusters to parallel clients( usually 5 running at the same time). So the number of the total clusters is 3X5=15. Depending on the cluster size, let’s say 4 VMs for each cluster, we need at least 15*4=60 VMs. Since workers are spot VM, they need more time to request and re-request if lost. The above example is the simplest case, some pipelines are more complex, maybe need hundreds VMs.
- The cluster on Bronze tier is utilized with low performance due to the use of zip format. I will talk about it later.
Solution:
Option 1: Create two High Concurrency clusters. One for Bronze, Silver, Another for Gold.
- Pro: Cluster starts time significantly reduced. On-demand cluster only lanuch once within the period of the batch. Based on our test, the overall pipeline running time was reduced by 50%. And the cost was reduced by 10-20%.
- Con: All pipelines run on the same cluster. You have to monitor the cluster size and memory usage to reallocate the size of clusters although auto-scale and round-robin can provide great help to prevent system crashes. You also need to optimize the code to reduce the pressure on the driver. We found lots of delays in this mode due to the bad code on the driver.
Option 2: Move pipeline into workflow on databricks.
- Pro: the workflow in databricks can reuse job-cluster. So Bronze, Silver, and Gold can run on the same cluster by clients.
- Con: We need to move pipelines from ADF to workflow in databricks. Even it is only time matters, there is another issue, unbalance of usage between 3 tires within the same workflow. Maybe we can leverage auto-scale to fix unbalance between Gold and the other two tiers, but auto-scale needs time also, and that time may be longer than the code itself.
Issue 2. Zip format is not supported well in databricks.
We used to use zip format to collect data from client servers since the period of on-premise. We kept this format on the cloud using AZcopy to upload the same files to the staging area then processed them in ADF pipelines. But databricks didn’t support zip format well, the unzip command can only run on the driver.
Solution:
Option 1: Directly upload log files that used to be compressed as zip files into Data lake through . Since lots of logs, the organization of the folder based on timestamps, like yyyy/mm/dd/hh/MM/ss. then use Autoloader to load them.
- Pro: Simple solution. easy to implement on Azure.
- Con: The size of the file maybe affect the cost and network. And small files affect the performance of data lake when we read them.
Option 2: Compress log files into a single parquet file rather than zip format. Upload parquet files to data lake and use autoloader to ingest them.
- Pro: Keep the same logic before on the client-server; quicker ingest into delta table; no small file issue.
- Con: need to query delta table or leverage other tools to recover original log files.
import pyarrow as pa
import pyarrow.parquet as pq
import glob
import os
folder_path = 'E:/Test/Upload/*.log' # the folder incudles all .dcu files
parquet_path = 'E:/Test/test.parquet' # single output file
os.remove(parquet_path)
schema = pa.schema([
('file_name',pa.string()),
('content', pa.binary())
])
pqwriter = pq.ParquetWriter(parquet_path, schema, compression='SNAPPY',write_statistics=False)
# list all files
file_list = glob.glob(folder_path)
for file in file_list:
with open(file, mode='rb') as file: # b is important -> binary
fileContent = file.read()
pa_content = pa.array([fileContent])
pa_filename = pa.array([file.name])
# pylist = {'content':fileContent}
table = pa.Table.from_arrays([pa_filename,pa_content],names = ['file_name','content'])
pqwriter.write_table(table,)
# close the parquet writer
if pqwriter:
pqwriter.close()Option 3: Use the Streaming solution. We can create an Event hub capture to receive logs from client-sever and connect with autoloader.
https://www.rakirahman.me/event-hub-capture-with-autoloader/
- Pro: Event-Driven solution. client log can be immediately processed once it is generated.
- Con: Need to change code on client-server, also not every client supports streaming due to security requirements.
Issue 3. Need a more flexible solution to trigger pipelines.
We used to create scheduled trigger / tumbling trigger on ADF. But the trigger itself doesn’t support reading metadata and dynamically adjusts trigger time or some parameters. We need to create a metadata table to easily maintain the triggers for each client + reports/pipeline.
Option 1: Use Azure function to call rest API. The azure function can get the metadata from any source.
https://docs.microsoft.com/en-us/rest/api/datafactory/pipelines/create-run
- Pro: Easy to implement and very flexible with coding.
- Con: If we put too much logic to trigger different pipelines, it is not as clear as the ones in ADF. And we lost some monitor features which are helpful in ADF unless you want to recreate these features.
Option 2: Leverage airflow to control pipelines.
- Pro: TBD
- Con: TBD
Issue 4. Legacy Python code to databricks.
There is some python code to process the data row by row. and covert these rows to multiple rows. By the content of each row, the logic may vary. We can easy to think to use UDF directly to leverage this old python code. But this way is very low efficient especially when the UDF contains lots of subfunctions.
Option 1: Use Azure Batch on cluster. We can split all rows into multiple tasks, then push these tasks into workers to process them. the worker is still running legacy python code, then output the results and merge them together.

- Pro: No need to change the python code.
- Con: How to efficiently split tasks running on workers. And Python may be too slow.
Option 2: Use Databricks native pyspark. We need to split the incoming dataset into several small subsets. Then use different logic to process each of them.
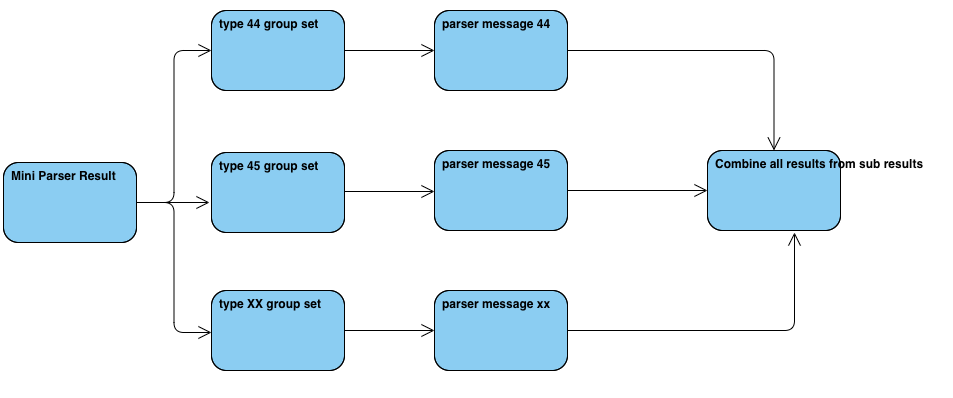
- Pro: Native pyspark/Scala is much quicker than UDF.
- Con: Need a smart solution to handle different logic to avoid if-else logic. (TBD)
Leave a Reply