While switching to the cloud, we found some pipelines running slowly and cost increased rapidly. To solve the problems, we did flowing steps to optimize the pipelines or data structures. They are all not hard to be implemented.
1. Set the different triggers for different recurring periods.
No matter for what reason, it is very common that one data pipeline is triggered recursively. However, the sources of this data pipeline may be refreshed with different frequency. In this case, we may set two triggers for this pipeline. So that this pipeline doesn’t have to run on the highest frequency.

2. Set the different pools for notebooks.
Databricks provides pool to efficiently reuse the VMs in the new created clusters. However, one pool can only has one type of instance. If we set pool instance too small, the out of memory or slow process will occur, while if the pool instances are too big, we are wasting our money.
To solve this problem, we set two kinds of pools. The heavy one with instance of 4 cores, 28GB. the light one with instance of 4 core, 8GB memory. For some light weight job, like ingest the source files into bronze table, the light one is a better choice. while the heavy weight one could be use to some aggregation work.

3. Create second hand index or archive folder for the source files.
At the beginning of switching to the cloud, we put everything into a single folder. It is fine for azure. But once we need to scan the spec files or get the location of the file, the huge number of files in this folder will significantly effect the performance, the situation will become worse as file number increase with time. To solve this problem. we have three solutions:
- create second hand index when file moves into the folder. The second hand index like a table which records the important information of the file, like name, modify date, location in datalake. So next time, when someone need to scan the folder, he only need to scan this second hand index rather than the whole blob dictionary.

- Archive the files. The maybe the easiest one, coz you only need to put the files that you would never use into archive folder. Then you are not time sensitive to get the files back from archive folder.
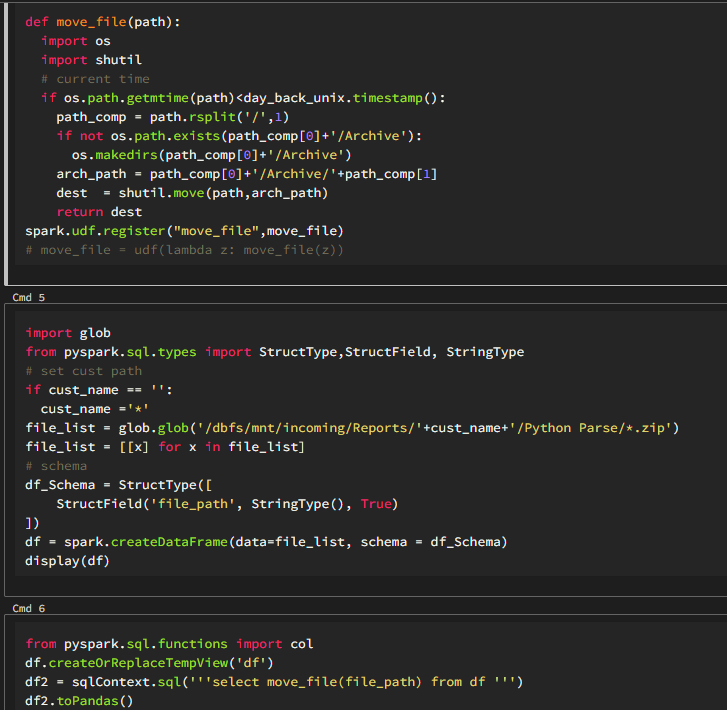
- Organize files by its receive date. This method is similar with the archive one. but we created many archive folders by date.

4. Optimize delta table weekly.
Don’t hesitate to do optimize/vacuum your delta table regularly. The small file will kill the advantage of delta table especially in the “Merge” operation. Following is the example of creating a delta table list that need to be optimized.
delta_table_list = ['customer','job','job-category','job_subscription','missing_file_check','parameter']
# optimize bronze table
for delta_table in delta_table_list:
sql_string = '''optimize delta.`/mnt/eus-metadata/{0}`'''.format(delta_table)
sqlContext.sql(sql_string)
for delta_table in delta_table_list:
sql_string = '''VACUUM delta.`/mnt/eus-metadata/{0}`'''.format(delta_table)
sqlContext.sql(sql_string)
Leave a Reply