SCD II is widely used to process dimensional data with all historical information. Each change in dimensions will be recorded as a new row configurated valid time period which usually on the date granularity. Since SCD II only keeps the changes, it significantly reduce the storage space in the database.
Everything looks fine, until big data coming. A flaw has been amplified. That is delay arriving dimensions. In SCD II,, you have to do a complex steps to process both dimension and fact data for delay arriving dimensions.
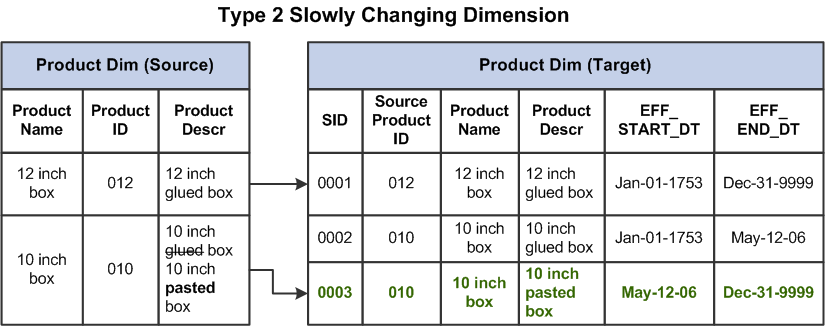
For Dimension(SCDII table) , we have to change retro rows in SCDII.
In the example above, for product ID=010, if we have any change before May-12-06, see April-02-06. And this change is delayed after SID=003. We have to :
- Scan the dimensional table, find SID = 0002 and 0003
- change End_DT of SID(002) to April-02-06
- insert a new record, SID=004, Start_DT=April-02-06, End_DT=May-12-06
For Fact table, we have to change multiple historical data
Update all FK of SID in fact table to 004 where the time period between April-02-06 and May-12-06
It maybe not a problem to execute “UPDATE” process in Row stored table, but in the big data area, most storage format leverages “column stored”, which has great advantage for searching operation, but low efficient on updating. The good news is we don’t have to “UPDATE” data nor to detect the changes on dimension. The only thing we need to do is snapshot the daily dimension data. Since for each day, we have the whole backups, it also much easier for fact table joining the dimension: date-to-date mapping. That’s is all!
The example above will become like :
| Date | Source Product ID | Product Name | Product descr |
| May-12-06 | 010 | 10 inch Box | 10 inch Glued box |
| May-12-07 | 010 | 10 inch Box | 10 inch pasted box |
| May-12-08 | 010 | 11 inch Box | 11 inch pasted box |
Would it has much redundancy in disk? No. Since we use column stored table, duplicated data in the same column is only saved once physically. Also the big data storage price is much cheaper than the traditional database.
Would it slow down the join due to much more data created in dimension table? No. There is another easy solution call “PARTITON“. Basically, we can partition the data by date, so that each partitioned folder presents a set of data group for that day.

“PARTITION” is transparent for the query. for example, when we execute query :
Select * from product
where product_name ='10 inch Box' and Date ='May-12-06'It will firstly go to the folder “Date =’May-12-06′“, rather than scan the whole table, then find the column “product_name =’10 inch Box’”. The partition operation is not only one level, you can create multiple levels.
Would it be faster to join the fact table? Yes. Once fact table is also partitioned by same column, e.g, date. Then we can easily mapping two date columns in dimension and fact. The scan processing is super quick. * some new tech, like delta table, you have to manually indicate the partition.
Conclusion
Transitional SCD is existing for a long time, the environment and prerequisites have been changed a lot to apply this method. I think snapshot is a better, faster and simpler solution in the big data.
Reference:
Functional Data Engineering – A Set of Best Practices | Lyft, Watch Functional Data Engineering – A Set of Best Practices | Lyft – Talk Video by Maxime Beauchemin | ConferenceCast.tv
Building A Modern Batch Data Warehouse Without UPDATEs | by Daniel Mateus Pires | Towards Data Science, Building A Modern Batch Data Warehouse Without UPDATEs | by Daniel Mateus Pires | Towards Data Science
Slowly Changing Dimensions (SCDs) In The Age of The Cloud Data Warehouse (holistics.io), Slowly Changing Dimensions (SCDs) In The Age of The Cloud Data Warehouse (holistics.io)
Leave a Reply