
1990, engineers were fighting for optimizing code performance and increasing CPU speeds.
1994, MPI started to be the dominant model used in high-performance computing.
2002, we started to leverage multi-cores processor to parallel computing.
2006, Hadoop opened a door of reliable, scalable, distributed computing using simple programming models in clusters.
2007, NVIDIA released first version of CUDA which enabled GPU for general purpose processing
2011, Kafka provided streaming solutions for handling real-time data feeds.
2014, Spark improved Hadoop, provides in-memory unified analytics engine with several enrichment libraries.
2019, Google scientists said that they have achieved quantum supremacy. We jumped out world of 0/1.
When we look back the evolution of these 30 years, there are two things taking the major role: Parallel and Redundancy. According to vocabulary.com, Parallel means two or more lines that never intersect; while Redundancy means needlessly repeated. Why are they so important in computing evolution?
In the real word, an efficient team can make things easier than working along only due to more people. like 100 farmers can work on a farm at the same time with one person per line. Similarly, computing can achieve excellent improvement by splitting tasks into multi parallel “workers” . Modern CPU and GPU can split tasks into cores; big data related platform can split tasks into nodes of clusters; even in the quantum computer, it leverages superposition state to let single qbit process multi tasks at the same time. In rick and morty, there is an actor “time police”, who can exist in multi parallel time line.

So, why parallel is so powerful, we still need redundancy? According to Murphy’s Law, “Anything that can go wrong will go wrong”. Fragile is a common thing in whole universe. To anti-fragile, we have to use redundancy. More fragile things have more redundancy to anti-fragile. We human have two eyes, two lungs, two kidneys. Most insects spawn hundreds to then thousands eggs to keep them survive.
Before the age of big data, redundancy is also wildly used in the IT area. The wild-known case is CRC and RAID1. Cyclic redundancy check (CRC) is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to raw data since signal may be easily interfered/lost within environment especially through wireless or internet. RAID 1 consists of an exact copy (or mirror) of a set of data on two or more disks to avoid some accident data lost.
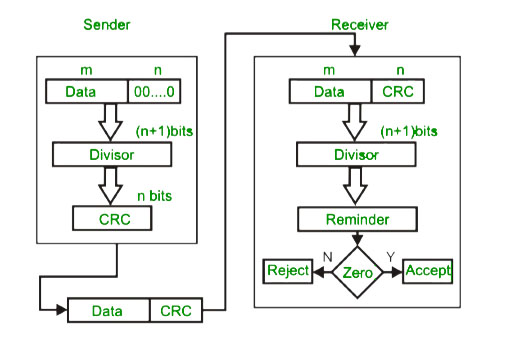
Another Redundancy cased is Non-SQL. Not like SQL 3nf, the intention of Non-SQL is high reading speed. Non-SQL improves the performance by adding redundancy so that we don’t have to waste time to join the tables.

After we headed to the age of big data, more and more “distributed” technologies are used to make work faster and parallel. But distributed itself is not as solid as we think. It bases on unstable network, easy broken storage devices and even sometime a natural disaster will destroy all your data. So redundancy is coming for anti-fragile as a brother of parallel. It creates extra “backups” in multi workers in the cluster that big data running. We are not only distributed computing but also distributed storage. Even we lost data in one worker, we immediately have same “backups” running in other workers.


Redundancy can also accelerate parallel process, specially hardware redundancy. Since we have replicas on two more places, the parallel requests can extract the same data from different place to balance the load and improve the I/O. There are two good examples: 1. Access google.com, there must be a load balancer to control which server we will connect to. 2. Read data from hadoop, a piece of data stored in the different servers, but we can extract all of them at the same time.
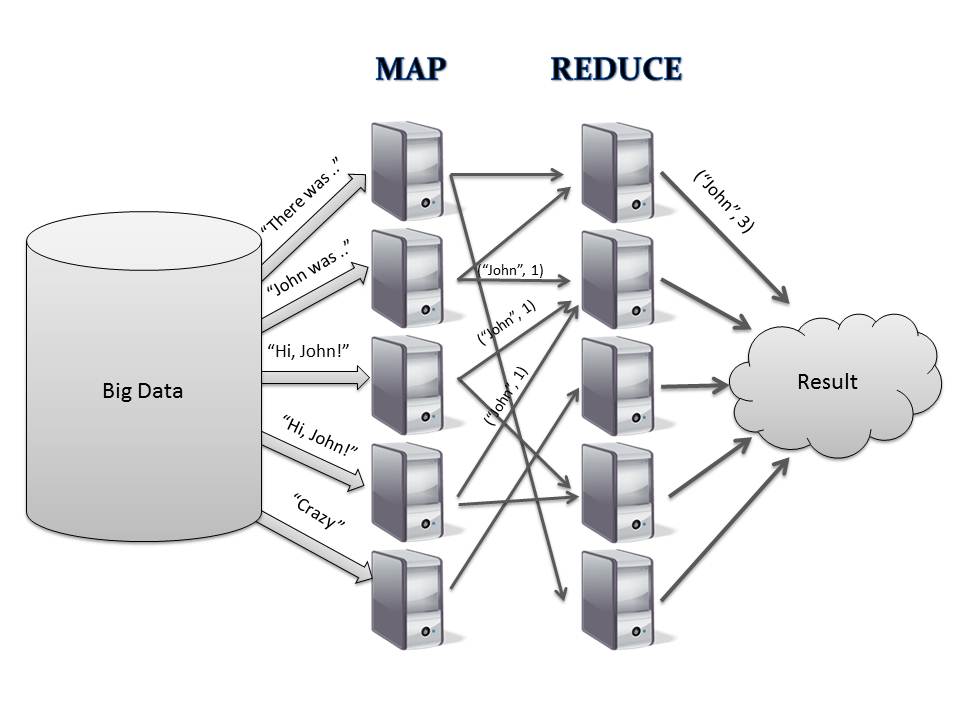
Parallel and Redundancy like twins. Lots of great new technologies in big data are related with both two concepts. The difference I feel is where they implement the “distribute”. in GPU, CPU, or clustered cpu/gpu/memory/disk…
Reference:
Redundancy in Cloud Computing Means Checking Four Areas (atsg.net)
How Redundancies Increase Your Antifragility | The Art of Manliness
Leave a Reply