Recently we get the work to improve the ETL efficiency. The latency mostly happen in I/O and file translation, since we only use one thread to handle it. So we want to use multi processing to accelerate this task.
Before everything, I think I need to introduce the difference between multi processing and multi threading in python. The major distance is multi threading is not parallel, there can only be one thread running at any given time in python. You can see it in blew.
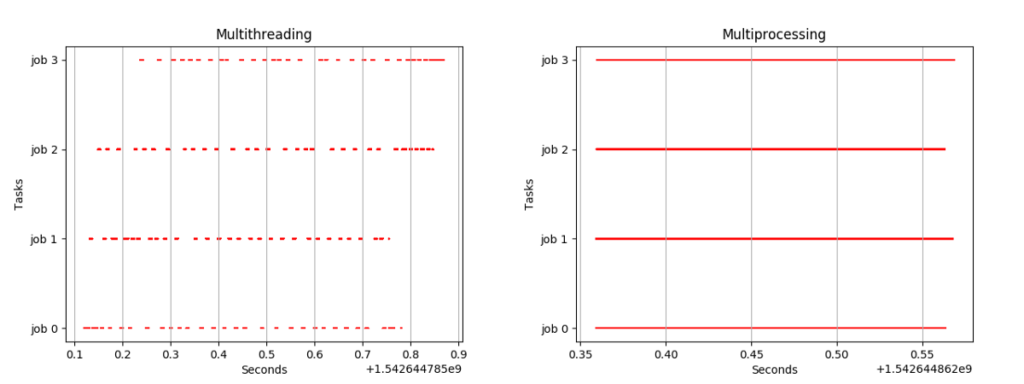
- Actually for CPU heavy tasks, multi threading is useless indeed. However it’s perfect for IO
- Multiprocessing is always faster than serial, but don’t pop more than number of cores
- Multiprocessing is for increasing speed. Multi threading is for hiding latency
- Multiprocessing is best for computations. Multi threading is best for IO
- If you have CPU heavy tasks, use multiprocessing with n_process = n_cores and never more. Never!
- If you have IO heavy tasks, use multi threading with n_threads = m * n_cores with m a number bigger than 1 that you can tweak on your own. Try many values and choose the one with the best speedup because there isn’t a general rule. For instance the default value of m in ThreadPoolExecutor is set to 5 [Source] which honestly feels quite random in my opinion.
In this task, we utilized multi processing.
Pro:
- 5x-10x faster than single core when utilizing 20 cores. (6087 files, 27s (20 cores) vs 180s(single core)
- no need to change current coding logic, only adapt to multiprocess pattern.
- no effect to upstream and down stream.

Corn:
- need to change code by scripts, no general framework or library
- manually decide which part to be parallel
How to work:
- Library: you need to import these libraries to enable multi processing in python
from multiprocessing import Pool
from functools import partial
import time # optional- Function: you need two functions. parallelize_dataframe is used split dataframe and call multi processing, multiprocess is used for multiprocessing. These two function need to put outside of main function. The yellow marked parameters can be changed by needs.
# split dataframe into parts for parallelize tasks and call multiprocess function
def parallelize_dataframe(df, func, num_cores,cust_id,prodcut_fk,first_last_data):
df_split = np.array_split(df, num_cores)
pool = Pool(num_cores)
parm = partial(func, cust_id=cust_id, prodcut_fk=prodcut_fk,first_last_data=first_last_data)
return_df = pool.map(parm, df_split)
df = pd.DataFrame([item for items in return_df for item in items])
pool.close()
pool.join()
return df
# multi processing
# each process handles parts of files imported
def multiprocess(dcu_files_merge_final_val_slice, cust_id,prodcut_fk,first_last_data):- Put another script into main function, and utilize parallelize_dataframe to execute.
if __name__ == '__main__':
.......
......
# set the process number
core_num = 20
rsr_df = parallelize_dataframe(dcu_files_merge_final_val,multiprocess,core_num, cust_id, prodcut_fk,first_last_data)
print(rsr_df.shape)
end = time.time()
print('Spend:',str(end-start)+'s')I can’t share the completed code, but you should understand it very well. There are some issues that I have not figure out the solution. The major one is how to more flexible to transmit the parameters to the multicore function rather than hard coding each time.
update@20190621
We added the feature that unzip single zip file with multi processing supporting utilizing futures library.
import os
import zipfile
import concurrent
def _count_file_object(f):
# Note that this iterates on 'f'.
# You *could* do 'return len(f.read())'
# which would be faster but potentially memory
# inefficient and unrealistic in terms of this
# benchmark experiment.
total = 0
for line in f:
total += len(line)
return total
def _count_file(fn):
with open(fn, 'rb') as f:
return _count_file_object(f)
def unzip_member_f3(zip_filepath, filename, dest):
with open(zip_filepath, 'rb') as f:
zf = zipfile.ZipFile(f)
zf.extract(filename, dest)
fn = os.path.join(dest, filename)
return _count_file(fn)
def unzipper(fn, dest):
with open(fn, 'rb') as f:
zf = zipfile.ZipFile(f)
futures = []
with concurrent.futures.ProcessPoolExecutor() as executor:
for member in zf.infolist():
futures.append(
executor.submit(
unzip_member_f3,
fn,
member.filename,
dest,
)
)
total = 0
for future in concurrent.futures.as_completed(futures):
total += future.result()
return totalRef :
Multithreading VS Multiprocessing in Python, https://medium.com/contentsquare-engineering-blog/multithreading-vs-multiprocessing-in-python-ece023ad55a
Fastest way to unzip a zip file in Python, https://www.peterbe.com/plog/fastest-way-to-unzip-a-zip-file-in-python
Leave a Reply