Since I started to play with cluster, I thought there was no mission which was not able to be completed by cluster. If there is, add another node. However, except Cuda on the sing-alone machine, I have been rarely touched GPU accelerated cluster as data engineer. Yes, maybe spark ML can utilize GPU since spark 3.0, but most jobs of DE are data pipeline and data modeling related. Until recently I googled “GPU ETL”, then it came out SPARK-RAPIDS, which leverage RAPIDS libraries to accelerate processes by GPU.
Easy to configure on Spark to gain advantage of GPU
I almost didn’t change anything from my original spark code( mixed pyspark, spark SQL, python and delta table access) to let it running on GPU cluster. That is a great thing! Everybody wants to get double with half work.The result of mine is speed up to 3.1mins(12 cores, 3 NVIDIA T4 GPUs, 84GB memory) from 5.4 mins(24 cores, 84GB memory). I think I can get better results if my inputs is bigger chunk of data like 500MB+ parquet.
Here is my configuration on databricks. You can also refer to this official document. ( however, I didn’t make cluster running by this document)
# cluster runtime version: 7.3 LTS ML (includes Apache Spark 3.0.1, GPU, Scala 2.12)
# node type: NCasT4_v3-series(Azure)
# spark config:
spark.task.resource.gpu.amount 0.1
spark.databricks.delta.preview.enabled true
spark.executorEnv.PYTHONPATH /databricks/jars/rapids-4-spark_2.12-0.5.0.jar:/databricks/spark/python
spark.plugins com.nvidia.spark.SQLPlugin
spark.locality.wait 0s
spark.rapids.sql.python.gpu.enabled true
spark.rapids.memory.pinnedPool.size 2G
spark.python.daemon.module rapids.daemon_databricks
spark.sql.adaptive.enabled false
spark.databricks.delta.optimizeWrite.enabled false
spark.rapids.sql.concurrentGpuTasks 2
# initial script path
dbfs:/databricks/init_scripts/init.sh
# create initial script on your notebook
dbutils.fs.mkdirs("dbfs:/databricks/init_scripts/")
dbutils.fs.put("/databricks/init_scripts/init.sh","""
#!/bin/bash
sudo wget -O /databricks/jars/rapids-4-spark_2.12-0.5.0.jar https://repo1.maven.org/maven2/com/nvidia/rapids-4-spark_2.12/0.5.0/rapids-4-spark_2.12-0.5.0.jar
sudo wget -O /databricks/jars/cudf-0.19.2-cuda10-1.jar https://repo1.maven.org/maven2/ai/rapids/cudf/0.19.2/cudf-0.19.2-cuda10-1.jar""", True)# some key configuration meaning
--conf spark.executor.resource.gpu.amout=1 # one executor per GPU, enforced
--conf spark.task.resource.gpu.amount = 0.5 # two tasks running on the same GPU
--conf spark.sql.files.maxPartitionBytes=512m # big batch is better for GPU efficient, but not too big which lead to out of memory issue
--conf spark.sql.shffle.partitons=30 # reduce partiton size from default 200 to 30. large size of partition is better for GPU efficient
--conf spark.rapids.sql.explain=NOT_ON_GPU # watch the log message output why a spark operation is not able to run on the GPUThe only problem I met till now was, when the notebook includes the view composed of delta tables, it would popped out error message “covert struct type to GPU is not supported”. Easily persist view to table can solve this problem. Overall, very cool plugin.
The magic of spark-rapids
There are two major features to let spark running on GPU through Rapids.
- Replace of CPU version ops with GPU version ops on the physical plan level.
- Optimized spark shuffle using RDMA and GPU-to-GPU directly communication.
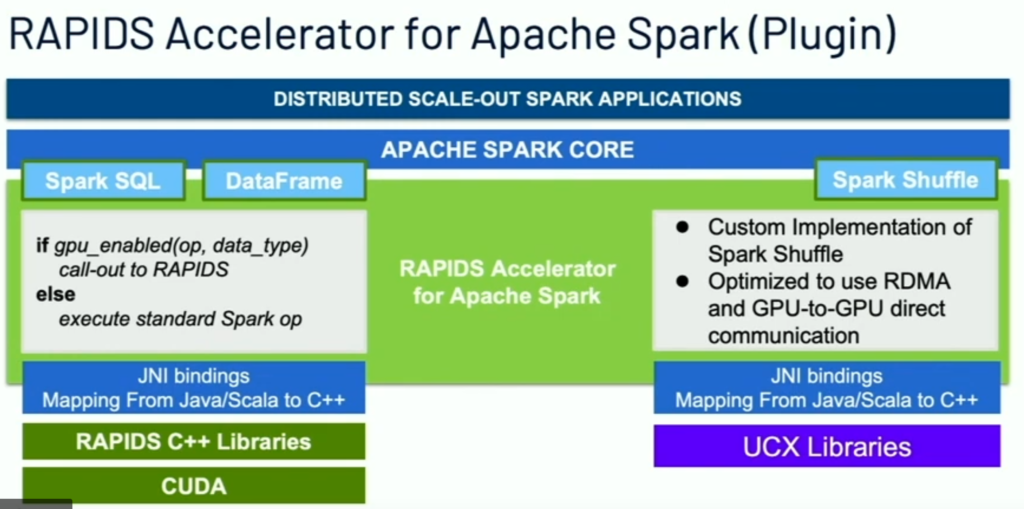
Since the replacing happens on the physical plan level, we don’t have to change the query. Even the operations are not supported by RAPIDS, it still can run on CPU.
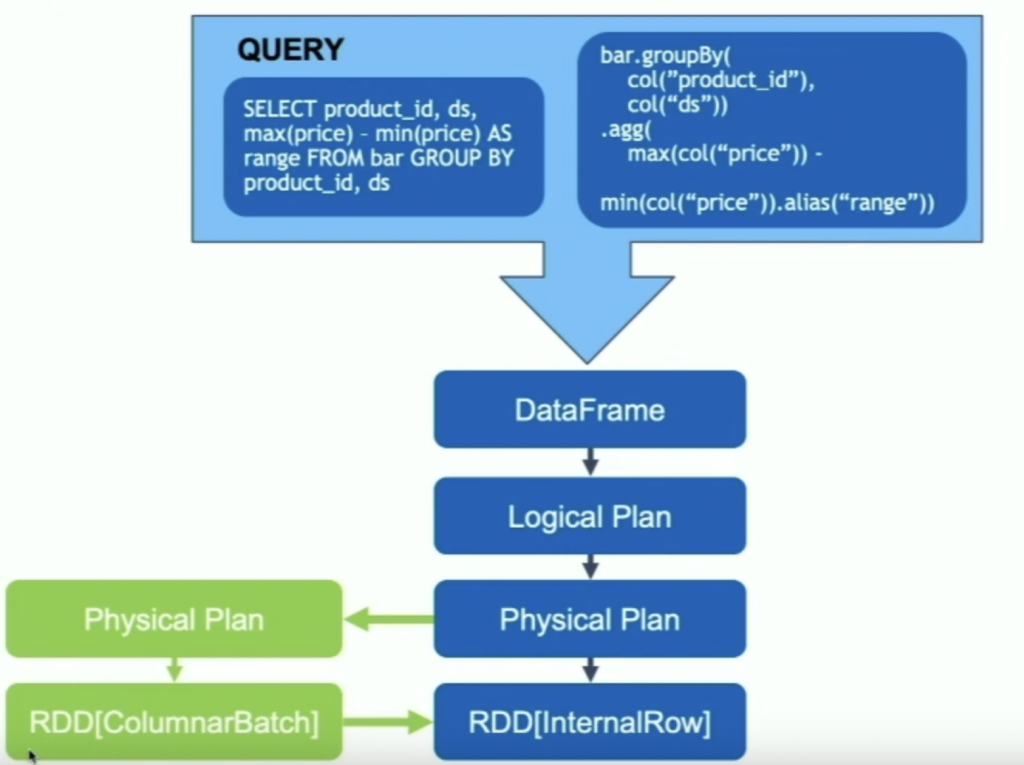
A CPU spark execute plan is like: logical plan —-> optimized by catalyst ——> optimize the logical plan in a series of phases —> physical plan —-> executed on cluster. While A GPU spark execute plan replaces operations on physical plan with GPU version and execute on the columnar batch.
If we look at the physical plan on GPU and CPU, we will find they are almost one to one match except some GPU-CPU data exchange ops, like GPUColumnarToRow, GPURowToColumnar.


Compare of two physical plans, we can find lots of operations have GPU version already. “Scan parquet” replaced by “GpuScan parquet”, since GPU needs columnar format, so it skipped “ColumnarToRow” which in CPU version. Then “Project” replaced by “GpuProject”. followed by “GpuColumnarToRow”, because next step “InMemoryTelation” was running on CPU. so on so forth.
Let’s talk about another great feature: Optimized spark shuffle.
Spark needs shuffle on wild transforms while narrow transforms grouped into single stage. Spark-Rapids implements a custom spark shuffle manager for its GPU clusters shuffle operation.It is able to:
- Spillable cache: it makes the data close to where it is produced, meanwhile it provides out of memory issue by moving data by the rule: GPU memory –> Host memory —> Disk.
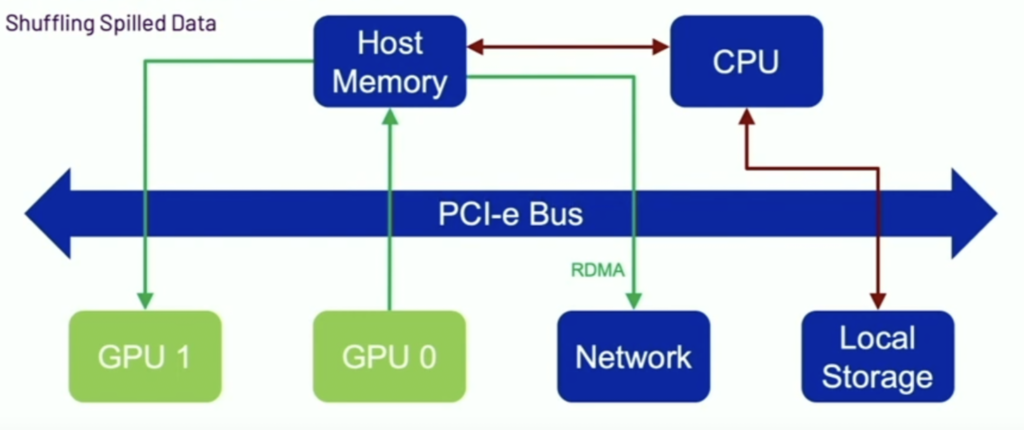
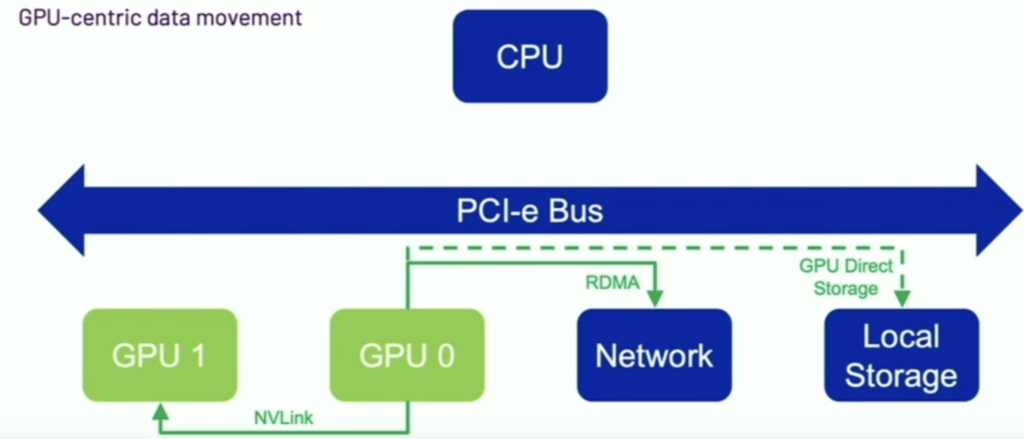
- Transport(shuffle): Handles block transfers between executors leveraging UCX libraries. ( see picture blew)
- GPU0-GPU0: cache in GPU0 , zero copy
- GPU0-GPU1: NVLink
- GPU0-GPUX(remote): RDMA
- Infiniband
- RoCE
- Disk- GPU: GPU direct storage(GDS)
Some helpful information from official Q&A:
What operators are best suited for the GPU?
- Group by operations with high cardinality
- Joins with a high cardinality
- Sorts with a high cardinality
- Aggregates with a high cardinality
- Window operations, especially for large windows
- Aggregate with lots of distinct operations
- Complicated processing
- Writing Parquet/ORC
- Reading CSV
- Transcoding (reading an input file and doing minimal processing before writing it out again, possibly in a different format, like CSV to Parquet)
What operators are not good for the GPU?
- small amouts of data( hundred MB)
- Cache coherent processing
- Data movement
- Slow I/O
- Back forth to CPU(UDFs)
- Shuffle
- Limited GPU Memory
What is Rapids
- a suit of open-source software libaraires and APIs for data science and data pipelines on GPUs.
- offering GPU dataframe that is compatible with ApacheArrow
- language independent columnar memory format
- zeo-copy streaming messaging and interprocess communication without serialization overhead
- Integrated with popluar framwworkd: PyTorch, Chainer, ApcheMxNet; spark, Dask
what is cuDF
- GPU accelerated data preparation and feature engineering
- python dropin pands replacement
- features
- CUDA
- low level libarary containing fuction implementations and c/C++ API
- importing/exporting Apache Arrow using the CUDA IPC mechanism
- CUDA kernels to perform element-wise math operations on GPU data frame columns
- CUDA sort, join, groupby and reductions oprations on GPU dataframes
- Python bindings
- a python libaray forr GPU dataframe
- python interface to CUDA C++ with addtional functionality
- Creating Apache arrow form numpy arrays, Pands, DF, PyArrow Tables
- JIT comppilation of UDFs using Numba
- CUDA
Reference:
Spark-Rapids, https://nvidia.github.io/spark-rapids/
ACCELERATING APACHE SPARK 3.X, https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-science/apache-spark-3/ebook-sign-up/
Getting started with RAPIDS Accelerator on Databricks, https://nvidia.github.io/spark-rapids/docs/get-started/getting-started-databricks.html#getting-started-with-rapids-accelerator-on-databricks
Deep Dive into GPU Support in Apache Spark 3.x, https://databricks.com/session_na20/deep-dive-into-gpu-support-in-apache-spark-3-x
Accelerating Apache Spark 3.0 with GPUs and RAPIDS, https://developer.nvidia.com/blog/accelerating-apache-spark-3-0-with-gpus-and-rapids/
RAPIDS Shuffle Manager, https://nvidia.github.io/spark-rapids/docs/additional-functionality/rapids-shuffle.html
UCX-PYTHON: A FLEXIBLE COMMUNICATION LIBRARY FOR PYTHON APPLICATIONS, https://developer.download.nvidia.com/video/gputechconf/gtc/2019/presentation/s9679-ucx-python-a-flexible-communication-library-for-python-applications.pdf
Unified Communication X, https://www.openucx.org/
Accelerating Apache Spark by Several Orders of Magnitude with GPUs, https://www.youtube.com/watch?v=Qw-TB6EHmR8&t=1017s
Leave a Reply