Since Microsoft upgraded WSL to version 2, it introduced full Linux kernel and full VM manage features. Except the performance benefit through deep integration with windows, WSL2 allows installing additional powerful apps like docker and upgrading Linux kernel anytime when it is available.
Two months ago, Microsoft with NVIDIA brought GPU acceleration to WSL2. This new feature made me exciting, so that we don’t have to train our models on a separated Linux machine or install dual OS startup.

Before I start, I did some search about basic ideas of virtualization and WSL2 GPU. It is good for me to understand how GPU paravirtualization works in WSL2.
Types of virtualization

- Full virtualization. In full virtualization, there is almost a complete model of the underlying physical system resources that allows any and all installed software to run without modification. There are two types of full virtualization.

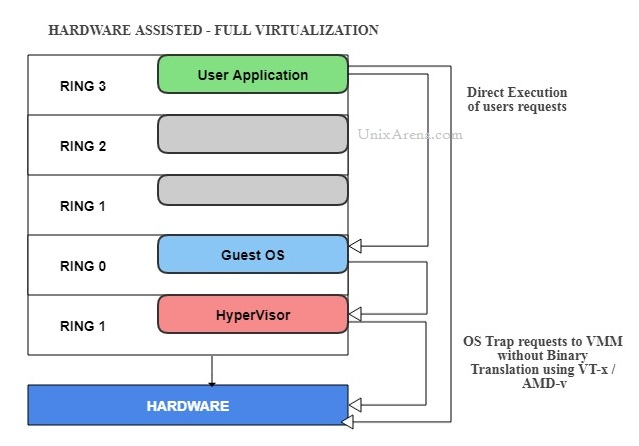
- Paravirtualization. Paravirtualization (PV) is an enhancement of virtualization technology in which a guest operating system (guest OS) is modified prior to installation inside a virtual machine (VM) in order to allow all guest OS within the system to share resources and successfully collaborate, rather than attempt to emulate an entire hardware environment. so the guests aware that it has been virtualized. products like Xen, IBM LPAR, Oracle VM for X86
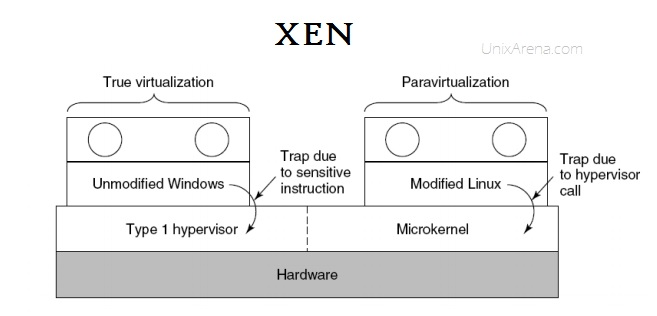
- Hybrid virtualization(hardware virtualized with PV drivers). virtual machine uses PV for specific hardware drivers(like I/O), and the host use full virtualization for other features. products like Oracle VM for x86, Xen.

- OS level Virtualization. aka containerization. No overhead . Products like docker, Linux LCX, AIX WPAR
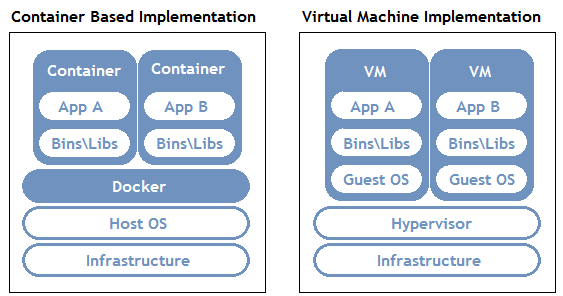
Except containerization, all virtualization use hypervisor to communicate with the host. We can take a look how hypervisor works blew.
- Hypervisor
- Emulation. (software full virtualization)
- emulate a certain piece of hardware which guest VM can only see.
- expense of performance since “common lowest” denominator
- need to translate instruction
- wide compatibility
- Paravirtualization
- only support certain hardware in certain configurations.
- Direct hardware access is possible
- Compatibility is limited
- hardware pass-through(hardware full virtualization)
- native performance, but need proper drivers for the real physical hardware
- hardware specific images
- GPU supported
- Emulation. (software full virtualization)
GPU Virtualization on Windows
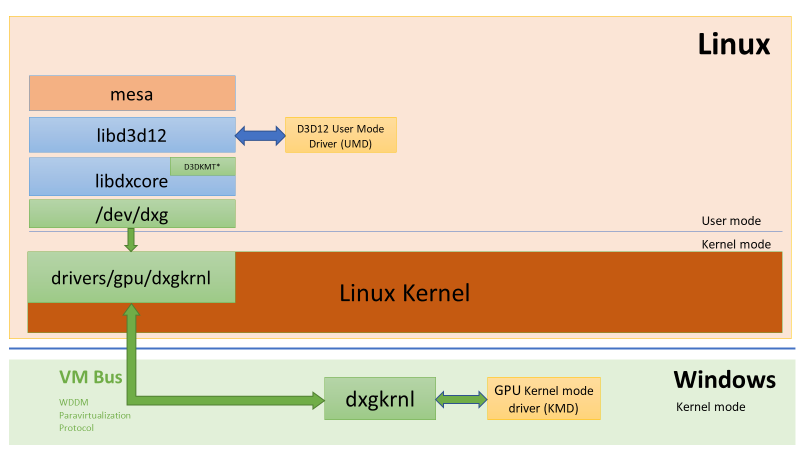
How it works on WSL
- a new kernel driver “dxgkrnl” which expoes “/dev/dxg” device to user mode.
- /dev/dxg mimic the native WDDM D3DKMT kernel service layer on Windows.
- dxgkrnl communicate with its big brother on Windows through VM Bus WDDM paravirtualization protocol.

DxCore & D3D12 on Linux
- libd3d12.so is compiled from the same source code as d3d12.dll on windows
- except Present() function, all others are same with windows.
- libxcore(DxCore) is a simplified version of dxgi
- GPU manufacturer partners provide UMD(user mode driver) for Linux

DirectML and AI Training
- DirectML sits on top of D3D12 API, provides a a collection of compute compute operations.
- Tensorflow with an integrated DirectML backend.

OpenGL, OpenCL & Vulkan
- Mesa library is the mapping layer which bring hardware acceleration for OpenCL , OpenGL
- vulkan is not supported right now.
Nvidia CUDA
- a version of CUDA taht directly targets WDDM 2.9 abstraction exposed by /dev/dxg.
- libcuda.so enables CUDA-X libaries such as cuDNN, cuBLAS, TensorRT.
- available on any glibc-based WSL distro

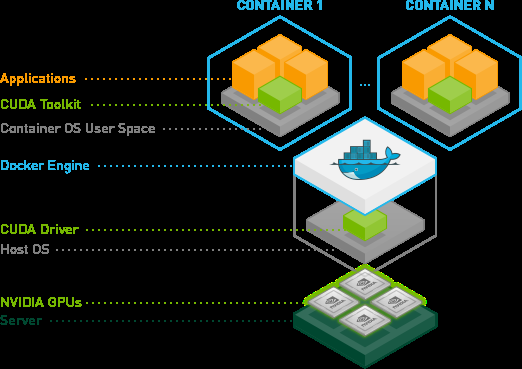
GPU container in WSL
- libnvidia-container libarary is able to detect the presence of libdxcore.so at runtime and uses it to detect all the GPUs exposed to this interface.
- driver store is a folder that containers all driver librarians for both Linux and Windows

GUI Application is still under developing.
How to enable GPU Acceleration in WSL
for the detail step, we can refer https://docs.nvidia.com/cuda/wsl-user-guide/index.html. Here I brief some keypoints:
- Windows version: 20150 or above (Dev Channel)
- Enable WSL 2
- Install Ubuntu On WSL
- Install Windows Terminal
- Upgrade kernel to 4.19.121 or higher
- NVIDA DRIVERS FOR CUDA ON WSL https://developer.nvidia.com/cuda/wsl/download
- Install docker in WSL:
- curl https://get.docker.com | sh
- You can see vmmen process on your windows task manger. It is the process for virtual machine in wsl2
- Install Nvidia Container Toolkit( nvidia-docker2)
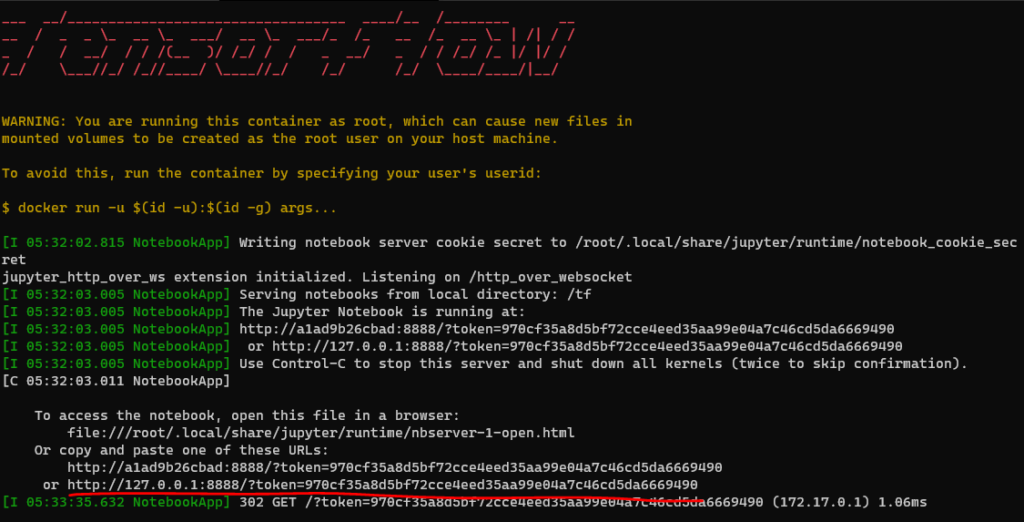
9. Start A TensorFlow Container
# test for docker
docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
# pull tersorflow image and run it
docker run -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyterAfter you pull tersoflow image, and run it. You can see following instruction:
Reference:
Para virtualization vs Full virtualization vs Hardware assisted Virtualization, https://www.unixarena.com/2017/12/para-virtualization-full-virtualization-hardware-assisted-virtualization.html/
Emulation, paravirtualization, and pass-through: what you need to know for client hypervisors, https://searchvirtualdesktop.techtarget.com/opinion/Emulation-paravirtualization-and-pass-through-what-you-need-to-know-for-client-hypervisors
DirectX is coming to the Windows Subsystem for Linux, https://devblogs.microsoft.com/directx/directx-heart-linux/
NVIDIA Container Toolkit, https://github.com/NVIDIA/nvidia-docker
CUDA on WSL User Guide, https://docs.nvidia.com/cuda/wsl-user-guide/index.html
NVIDIA Drivers for CUDA on WSL, https://developer.nvidia.com/cuda/wsl/download
Tensorflow image on Docker, https://www.tensorflow.org/install/docker
Leave a Reply