For some reason, there is a request to predict video frames. We need that video is a combination of spatial and temporal dimensions. FCN and LSTM are good for them respectively. But for both of them, we need to use ConvLSTM. Since I just start to learn it, so I write down some of notes for good understanding.
1.First thing first, let’s see what LSTM looks like:
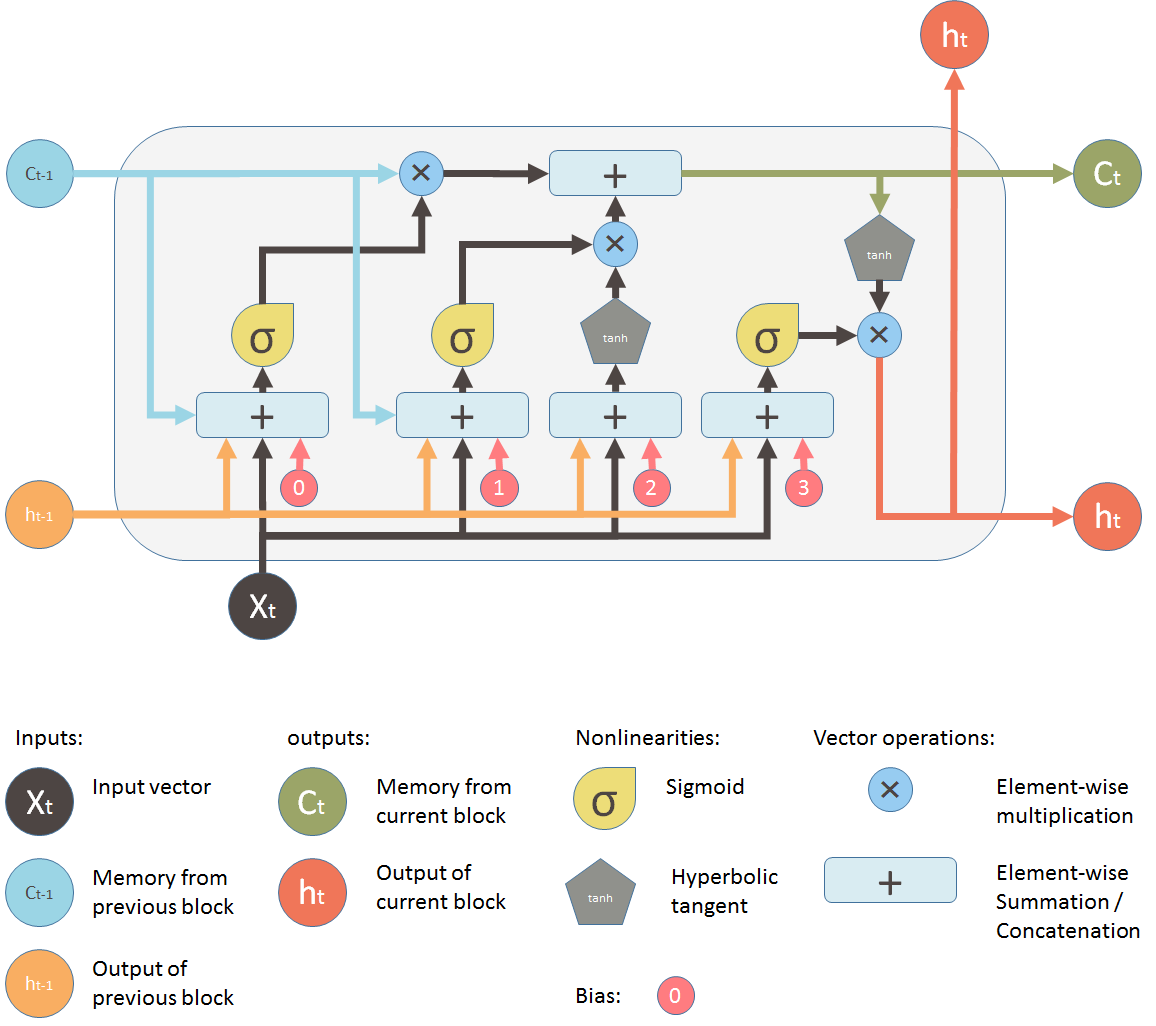
From left to right, we can see forget gate, input gate, input modulation gate and output gate. On the top side is memory pipe. It simulates the manner that human remember things. For more information, how the LSTM works please click here.
In keras, there are already three kinds of RNN: simpleRNN, LSTM and GRU. They are all easy to use.
2. What is ConvLSTM
Since LSTM is not good for spatial vector as input, which is only one dimension, they created ConvLSTM to allowed multidimensional data coming with convolutional operations in each gate.
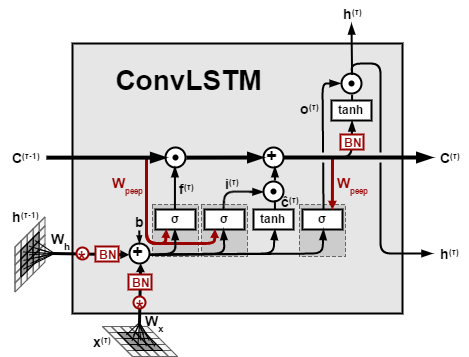
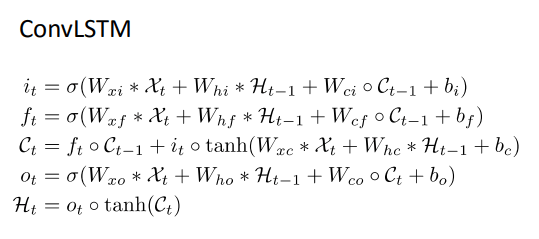
We can find the basic formulas are as same as LSTM, they just use convolutional operations instead of one dimension for input, previous output and memory. Keras needs a new component which called ConvLSTM2D to wrap this ConvLSTM.
3. Where we use it?
As I said in the beginning, it is used for prediction with time and space. The already done in academic inculds: predict precipitation, video frame prediction, some physic movement activities. You can find more in my reference.

Reference:
1. the bounce ball. https://www.youtube.com/watch?v=RjZ1VKYyHhs
2. weather forecast. https://papers.nips.cc/paper/5955-convolutional-lstm-network-a-machine-learning-approach-for-precipitation-nowcasting.pdf
3. some video prediction. https://www.youtube.com/watch?v=MjFpgyWH-pk
Leave a Reply