Columnstore is the most popular storage tech within big data. We must have already heard parquet, delta lake. They are both columnstore format which brings 10x times compress ratio and super faster query speed to analytic work. SQL server, one of fastest evolving relation database, also provides columnstore index with multiple optimizations.
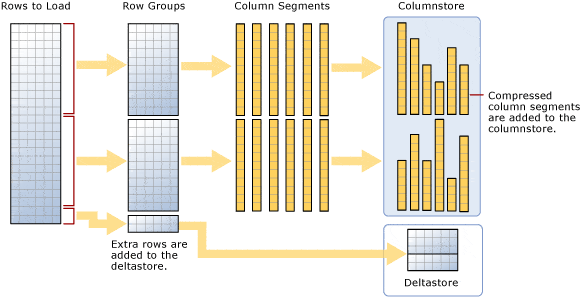
SQL server provides clustered and non-clustered columnstore index. Delta store is a clustered B-tree index used only with columnstore index automatically. It stores rows until the number of rows reaches a threshold(~1048576 rows) them moved data into columnsotre, and set state from Open to Closed. I will show you at the end of this article.
Clustered columnstore index
- Primary storage method for the entire table
- All columns are included, there is no keys.
- can only combined with non-clustered B-tree index to speed up
- queries that search for specific values or small ranges of values.
- updates and deletes of specific rows
- usually for fact table or large dimension tables
Non-clustered columnstore index
- We can indicate which columns to be indexed, usually for frequently used columns.
- requires extra storage to store a copy of columns in the index(~10%)
- can be combined with other index.
How to choose columnstore index?
Microsoft already provided the conventions on his document.

I would recommend use columnstored index for most of OLAP work, as we need fast query without much delete/update tasks.
How to delete large size of data from columnstore table
Although Microsoft doesn’t suggest us to delete more than 10% data from columnstore table, there is still have chance we have to. In this case, I summarized some of my experience.
| Delete from columnstore is a soft delete
If you tried to delete rows from columnstore table, you will not actually delete the data, but sql server will mark this row as deleted.
You can run sql blew to find out the number of delete rows and deltastore. Once there are too many row marked “delete”, then you have to rebuild/reorganize the columnstore table. Remember , it is not like Optimize clause in deltalake, which is more like bin-packing for small files.
SELECT
tables.name AS table_name,
indexes.name AS index_name,
partitions.partition_number,
column_store_row_groups.row_group_id,
column_store_row_groups.state_description,
column_store_row_groups.total_rows,
column_store_row_groups.size_in_bytes,
column_store_row_groups.deleted_rows,
internal_partitions.partition_id,
internal_partitions.internal_object_type_desc,
internal_partitions.rows
FROM sys.column_store_row_groups
INNER JOIN sys.indexes
ON indexes.index_id = column_store_row_groups.index_id
AND indexes.object_id = column_store_row_groups.object_id
INNER JOIN sys.tables
ON tables.object_id = indexes.object_id
INNER JOIN sys.partitions
ON partitions.partition_number = column_store_row_groups.partition_number
AND partitions.index_id = indexes.index_id
AND partitions.object_id = tables.object_id
LEFT JOIN sys.internal_partitions
ON internal_partitions.object_id = tables.object_id
AND column_store_row_groups.deleted_rows > 0
WHERE tables.name = 'table_name'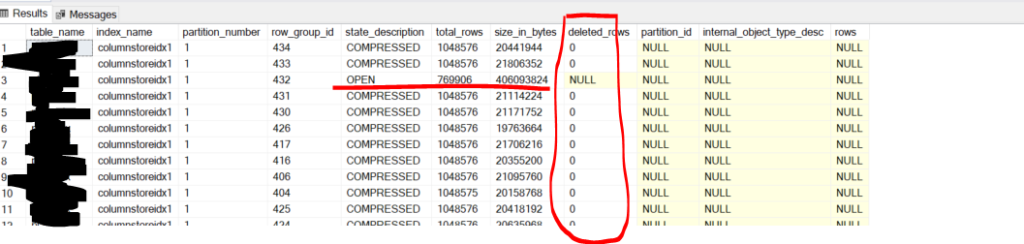
| Steps to delete large size of data in columnstored table
1. delete non-clustered B-tree index( after delete operation, rebuild it if needed)
If we run execution plan for bulk delete, you will find B-tree index related operations spend most of time rather than columnsotre index.

2. delete by a small batch
One of the down side of Azure SQL is we can not set log as simple. So it will take lots of transaction time when we try to delete a large table. The work around is delete by a small batch to make each log transaction smaller and quicker. Blew I gave an example to delete data by chunksize = 1000000.
deleteMore:
delete top(1000000) from table_name
where id%2=0
IF @@ROWCOUNT != 0
begin
print current_timestamp
goto deleteMore
end3. rebuild/reorganizing columnstored index if needed
Sometimes, we have to rebuild/reorganizing index if we delete too many data and it affects performance of query. here I give a snippet to show how to archive it.
-- rebuild column stored index
alter index indexname on table_name rebuild/reorgnize
alter index all on tablename rebuild/reorgnize
-- check fragment
SELECT a.object_id, object_name(a.object_id) AS TableName,
a.index_id, name AS IndedxName, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats
(DB_ID (N'schema_name')
, OBJECT_ID(N'table_name')
, NULL
, NULL
, NULL) AS a
INNER JOIN sys.indexes AS b
ON a.object_id = b.object_id
AND a.index_id = b.index_id;
GOReference:
Choose the best columnstore index for your needs. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-design-guidance?view=sql-server-ver15#choose-the-best-columnstore-index-for-your-needs
Columnstore indexes – Query performance. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-query-performance?view=sql-server-ver15
How to efficiently delete rows while NOT using Truncate Table in a 500,000+ rows table. https://stackoverflow.com/questions/11230225/how-to-efficiently-delete-rows-while-not-using-truncate-table-in-a-500-000-rows
Hands-On with Columnstore Indexes: Part 1 Architecture. https://www.red-gate.com/simple-talk/sql/sql-development/hands-on-with-columnstore-indexes-part-1-architecture/
Leave a Reply