–03/19/2019 version 0.1
Last week, my wife told me she logged into my netflix’s account, then she found it was not hers immediately since the items did not match her tastes. This activated my interesting in the recommendation system of Netflix & Youtube which are the most watched channels in US. (maybe spotfiy will be the same way). Here I want to give a brief analysis how they work.
Basic
Before we quickly look how many different manners(that I knew) used in the recommendation systems.

Popularity. This is the simplest way in term of PV. It works very good for new users and avoid the “cold start” problem. However, the downside is this method can not provide the personalized recommendation. The way to optimize it is adding some categories at the beginning so that users can filter the categories by themselves.
Collaborative filtering (CF). The Collaborative Filtering (CF) algorithms are based on the idea that if two clients have similar rating history then they will behave similarly in the future (Breese,Heckerman, and Kadie, 1998). It can also split into two subcategories, one is Memory-based, another is Model-based.
- Memory-based approach can be divided into User-based and Item-based. They find the similar users or similar items respectively in term of Pearson Correlation.
- User-based.
- Build correlation matrix
 which is symmetric.
which is symmetric. ![\[S(i,k)=\frac{\sum_j (v_{ij}-\bar{v_i})(v_{kj}-\bar{v_k})}{\sqrt{\sum_j (v_{ij}-\bar{v_i})^2(v_{kj}-\bar{v_k})^2}}\]](https://jie-tao.com/wp-content/ql-cache/quicklatex.com-9ff6b862e97b9ffd0922b947989119f1_l3.png "Rendered by QuickLaTeX.com")
- select top k users who has the largest scores.
- identify items that similar users like but the prediction user has not seem before. The prediction of a recommendation is based on the wighted combination of the selected neighbor’s rating.
![\[p(i,k)=\bar{v}_i+\frac{\sum_{i=1}^{n}(v_{ij}-\bar{v}_k)\times S(i,k)}{\sum_{i=1}^{n}S(i,k)}\]](https://jie-tao.com/wp-content/ql-cache/quicklatex.com-4d0390c328dd4cc3408bf9e909e2f957_l3.png "Rendered by QuickLaTeX.com")
- pick up top N of movies based on the predicted rating.
- Build correlation matrix
- Item-based.
- Build correlation matrix based on items. (similar to user-based)
- Get the top n movies that prediction user watched and rated before.
- return the movies that mostly related to these n movies and the prediction user has never watched.
- Build correlation matrix
- In the real word. The size of user are growing faster than item, and they are easy to be changed. So item-based are most frequency used.
- User-based.
- Model-based approach are based on matrix factorization which is popular in dimension reduction. Here we use Singular value decomposition(SVD) to explain.
, where U represents the freature vectors corresponding to the users in the latent space with dimension r, V represents the feature vectors corresponding to the items in the latent space with dimension r.![\[X_{n*m}=U_{n*r}\cdot S_{r*r}\cdot V_{r*m}^T\]](https://jie-tao.com/wp-content/ql-cache/quicklatex.com-6f08df33a9d74179914fe1be6f2ad4d6_l3.png "Rendered by QuickLaTeX.com")
 Once we find U and V, we can calculate any
Once we find U and V, we can calculate any  by
by  .
. - CF is based on historical data, it has “cold start” problem. and the accuracy of prediction is based on the mount of data since the CF matrix has sparsity problem, e.g, few mistake rating will effect the prediction seriously.
Contented-based(CB). This approach is based on the information of item itself rather than only rating in CF approach. We need to create meta data for the items. These meta data can be tagged manual or use TF-IDF tech to automatically extra keywords. Then build the connection between the item that prediction user liked and the items with similar meta data. CB avoid of “cold start” and “over recommend” problems, however, it is hard to metain and keep accuracy of meta data.
Hybrid. It combined CF and CB. We can merge the prediction together or set the weights in different scenarios.
Deep Learning. In the large scale dataset, it is hard to use traditional recommendation system because of 4V(volume, variety, velocity, and veracity). Deep learning model are good at solving complex problem( A review on deep learning for recommender systems: challenges and remedies). We will introduce deep learning model used by YouTube in the next section.
Netflix
I firstly log into the Netflix to find some information provided by the official website. Fortunately, there was a topic How Netflix’s Recommendations System Works. They didn’t give much detail about algorithms but the provides the clues which information they are using for predict users’ choices. Blew is their explanation:
We estimate the likelihood that you will watch a particular title in our catalog based on a number of factors including:
-
your interactions with our service (such as your viewing history and how you rated other titles),
-
other members with similar tastes and preferences on our service (more info here), and
-
information about the titles, such as their genre, categories, actors, release year, etc.
So, we can guess it is a hybrid approach combined with CF(item-base and user-based) and CB approaches. But we don’t know how they design it at this moment. Let keep reading from the official website.
In addition to knowing what you have watched on Netflix, to best personalize the recommendations we also look at things like:
-
the time of day you watch,
-
the devices you are watching Netflix on, and
-
how long you watch.
These actives are not mentioned in the basic section. They are all used as input vector for the deep learning model which we will see in YouTube section.
It also mentioned “Cold start” problem:
When you create your Netflix account, or add a new profile in your account, we ask you to choose a few titles that you like. We use these titles to “jump start” your recommendations. Choosing a few titles you like is optional. If you choose to forego this step then we will start you off with a diverse and popular set of titles to get you going.
It’s clear they use popularity approach with categories to solve “cold start” problem. As user has more historical information, Netflix will use another approaches to replace the initial one.
They also personalized row and title inside:
In addition to choosing which titles to include in the rows on your Netflix homepage, our system also ranks each title within the row, and then ranks the rows themselves, using algorithms and complex systems to provide a personalized experience. …. In each row there are three layers of personalization:
- the choice of row (e.g. Continue Watching, Trending Now, Award-Winning Comedies, etc.)
- which titles appear in the row, and
- the ranking of those titles.
They calculate the score for each item for each users, then sum up these scores into each category to decide the order of rows. As I said, we don’t know how they mix CB and CF to get the score of each item yet. But they are mixed for sure.
YouTube
As Google’s product, it is not surprised that YouTube uses Deep learning as a solution for recommendation system. It is too large both in user and item aspects. A simple stats model can not handle it well. In the paper “Deep Neural Networks for YouTube Recommendations“, they explained how they use DL to YouTube.
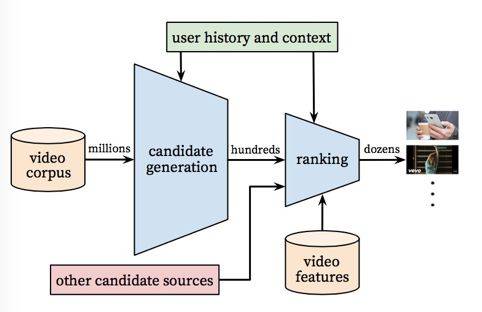
It has two parts: Candidate Generation and Ranking. One for filtering hundred candidates from millions, second for sorting by adding more scenario or video features information. Let’s see how they work:
- Candidate generation.
 For candidate generation, it filters from millions videos, so it only uses user activities and scenario information. The basic idea is getting probabilities of watching specific video V through user U and context C.
For candidate generation, it filters from millions videos, so it only uses user activities and scenario information. The basic idea is getting probabilities of watching specific video V through user U and context C.
. The key point is to get user vector![\[P(w_t=i|U,C)=\frac{e^{v_iu}}{\sum_{j\in{v}}e^{v_ju}}}\]](https://jie-tao.com/wp-content/ql-cache/quicklatex.com-4152ce1bd4b1b769fd0e2849238697a8_l3.png "Rendered by QuickLaTeX.com")
 and
and  . To get user vector , author embeds the video watches and search tokens, then average them into watch vector and search vector, then combined with other geogrphic , video ages and gender vectors to get through 3 connected ReLU layer. The output is user vector . To get video vectors , we need to use to predict probabilities for all through softmax. After training, the video vector is what we want. In the serving processing, we only need to put and together to calculate the top N highest probability vectors.
. To get user vector , author embeds the video watches and search tokens, then average them into watch vector and search vector, then combined with other geogrphic , video ages and gender vectors to get through 3 connected ReLU layer. The output is user vector . To get video vectors , we need to use to predict probabilities for all through softmax. After training, the video vector is what we want. In the serving processing, we only need to put and together to calculate the top N highest probability vectors. - Ranking.
 Compared with Candidate Generation, the number of videos is much less. So we can put more video features into the embedding vectors. These features are mostly focus on scenario, like topic of video, how many videos the user watched under each topic and time since last watch. It embeds categorical features with shared embeddings and continuous features with powers of normalization.
Compared with Candidate Generation, the number of videos is much less. So we can put more video features into the embedding vectors. These features are mostly focus on scenario, like topic of video, how many videos the user watched under each topic and time since last watch. It embeds categorical features with shared embeddings and continuous features with powers of normalization.
Reference:
- Deep Neural Networks for YouTube Recommendations, Paul Covington, Jay Adams, Emre Sargin, https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf
- How Netflix’s Recommendations System Works, n/a, https://help.netflix.com/en/node/100639
- Finding the Latent Factors | Stanford University, https://www.youtube.com/watch?v=GGWBMg0i9d4&index=56&list=PLLssT5z_DsK9JDLcT8T62VtzwyW9LNepV
- Recommendation System for Netflix, Leidy Esperanza MOLINA
FERNÁNDEZ, https://beta.vu.nl/nl/Images/werkstuk-fernandez_tcm235-874624.pdf - 现在推荐算法都发展成什么样了?来看看这个你就知道了!,章华燕, https://mp.weixin.qq.com/s?__biz=MzIzNzA4NDk3Nw==&mid=2457737060&idx=1&sn=88ef898f5054ae9b8cb005c31b65ee2d&chksm=ff44bf3ac833362c2436002be265c390b033d3e7709553fd8b603e6269d58f366f689beb2639&mpshare=1&scene=1&srcid=#
Leave a Reply