It’s a little bit late to talk about Kafka, since this technology has been widely used for a long time. These days, I finally has time to learn it ans summary the major concepts inside. In this nutshell, I will split the page into three parts: why do we need it, basic concepts and how it works.
Why do we need Kafka?
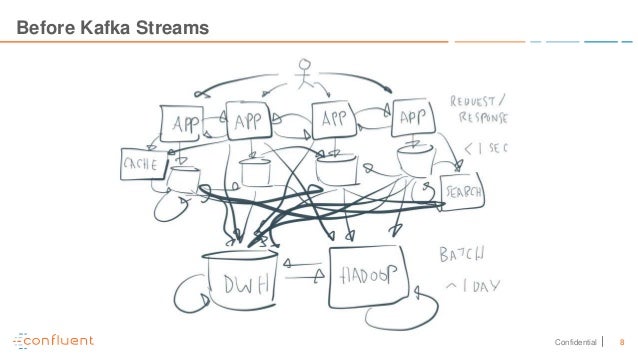
As we have more and more systems merged into a big network structure. and each system has their own protocols and communication methods. we have to take more time and endure the super complex structure. At the end, the cost will be raised as well.

Kafka provides a central messaging bus with distributed, resilient and fault tolerant. Each source and target connects to kafka cluster as producers and consumers. They use same protocols to send and receive the messages(key-value and timestamp). We can seem it as a hybrid solution combining message system with distributed retention.
Concepts
Producers publish the data into kafka, it’s source of the data. which could be sensors, laptop, loT, logs etc.
- producers choose which records to assign to which partition within the topic ( topic is stream of data, like table in database; partition is part of topic. we will talk about them soon)
- Producers use round-robin or function to choose partition to archive load balance between nodes(brokers) in the cluster.
- targetPartition=utils.abs(utils.murmur2(record.key()))%numPartitions
- use murmur2 algorithm
Brokers are nodes/servers in the cluster. They are key features for kafka features like fault tolerance, high performance.
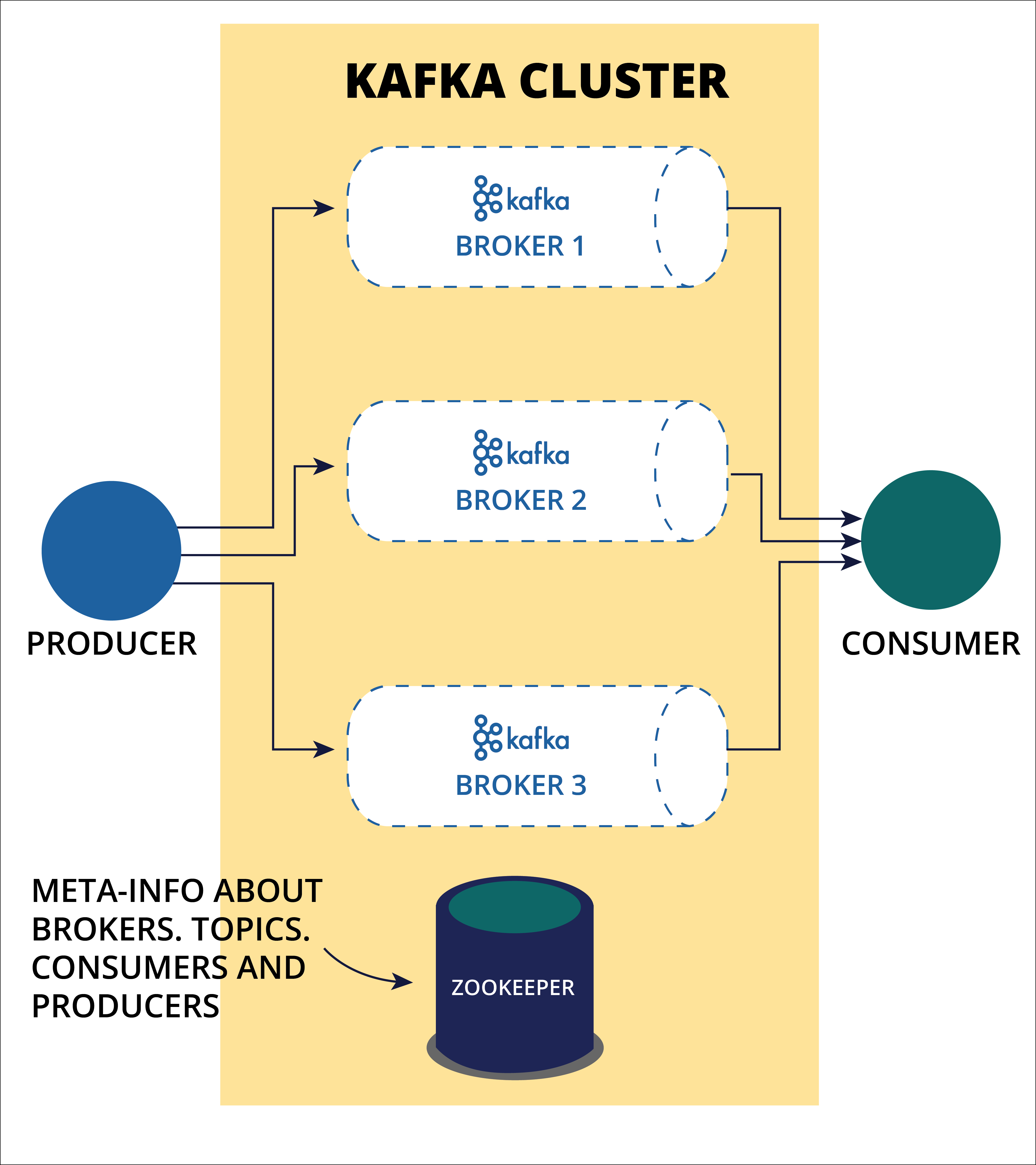
- broker identified by ID
- each brokers contains certain topic partitions
- connect any broker = connect to the entire cluster
- typically 3 or more brokers to achieve redundancy
- message in a topic are spread across partitions in difference brokers, each partition can be replicated aross multiple brokers
Consumers subscribe the message from kafka cluster.

- consumer can be a single receiver or a distributed cluster named consumer group
- a consumer group can read from topic in parallel
Topics are a particular stream of data which identified by its name. Each topic is split into partitions. We can set partition number and replication factor for each topic. Partition is ordered immutable sequence of records(messages) with their id named offset.

- offset’s order is only guaranteed in one partition
- data is kept only for a limited time(default is one week).
- partition is immutable
- consumer can choose any offset as start reading point, so that each consumer wouldn’t impact others.
Connector is used to connect between topics and app/database. A Source Connector (with help of Source Tasks) is responsible for getting data into kafka while a Sink Connector (with help of Sink Tasks) is responsible for getting data out of Kafka.
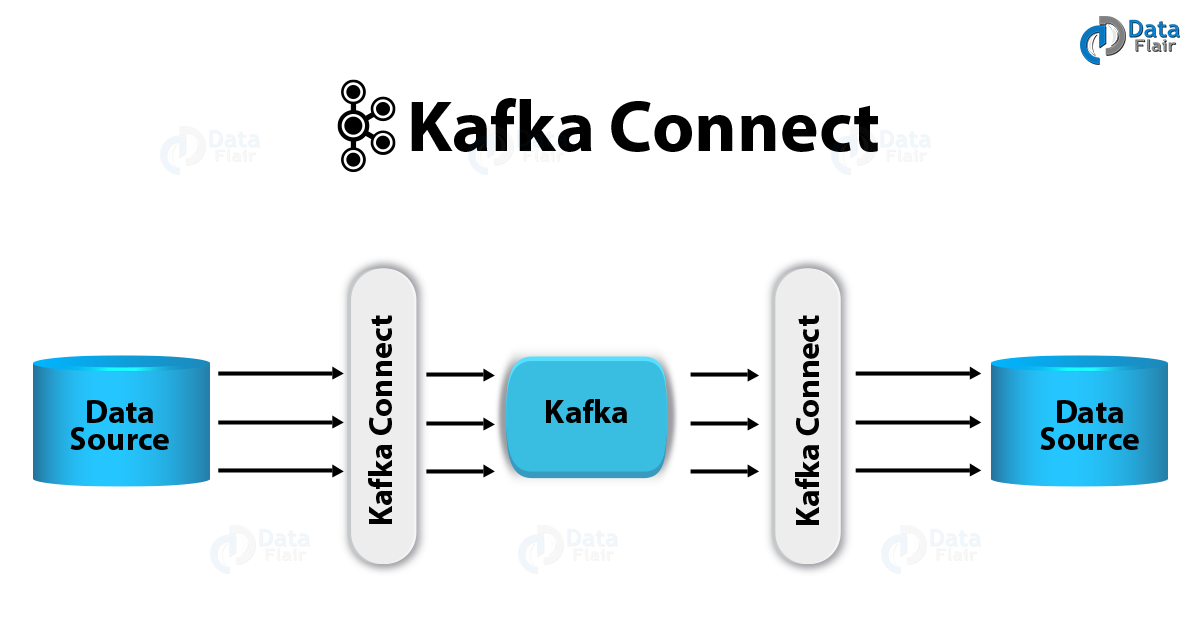
- stream an entire sql database to kafka
- stream kafka topics into hdfs
- recommend to leverage build-in connectors
How does it work?
Producer to kafka
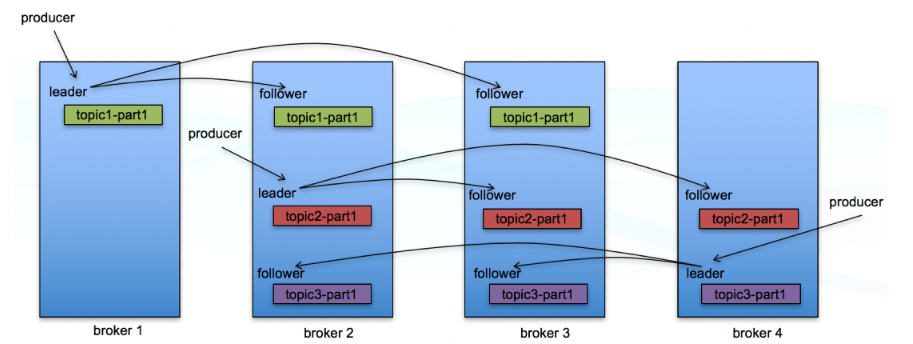
- Producer chooses topic and partition to send the inbound message into kafka.
- Topic splits into several partitions. Each partition has one broker as leader and zero or more brokers as follower named ISR (in sync replica) . Only the leader can receive and serve data for partitions. Other brokers will sync the data from the leader.
- A topic with replication factor N, it can tolerate up to N-1 server failures.
kafka to consumers
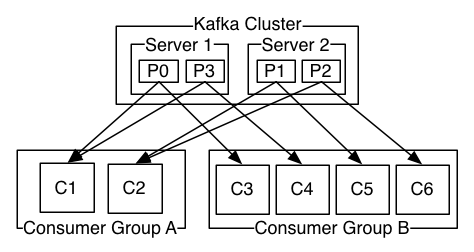
- As we mentioned ahead, consumer can be single node or consumer groups.
- if consumer number is greater than partitions number, some consumers will be idle.
- if consumer number is less than partitions number, some consumers will receive messages from multiple partitions.
- if consumer number is equal to partitions number, each consumer reads messages in order from exactly one partition
Data consistency and availability
- Partition
- Messages sent to a topic partition will be appended to the commit log in the order they are sent
- a single consumer instance will see messages in the order they appear in the log (message order only guaranteed in a partition)
- a message is ‘committed’ when all in sync replicas have applied it to their log
- any committed message will not be lost, as long as at least one in sync replica is alive.
- Producer options
- wait for all in sync replicas to acknowledge the message
- wait for only the leader to acknowledge the message
- do not wait for acknowledgement
- consumer options
- receive each message at most once
- restart from the next offset without ever having processed the message
- potentially message loss
- receive each message at least once
- restart and process message again. duplicate messages in downstream,
- no data loss
- ( recommended, downside stream handles duplicate message)
- receive each message exactly once
- transitional level
- re read the last transaction committed
- no data loss and no data duplication
- significantly decreasing the throughput using a transaction
- receive each message at most once
Architecture
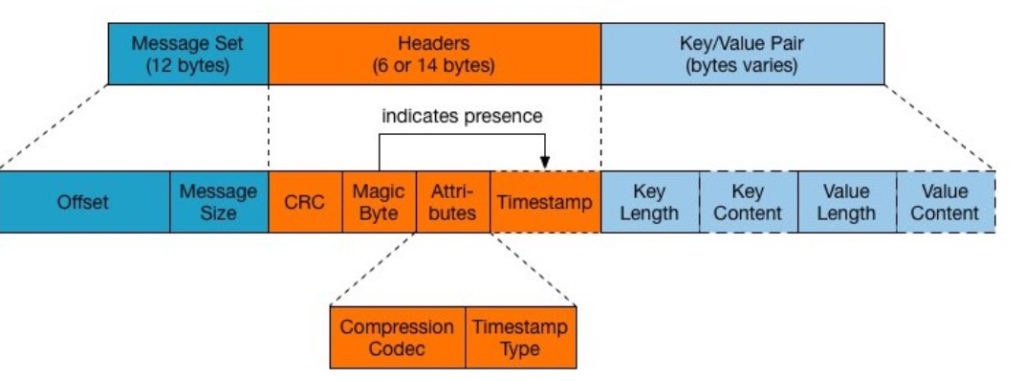
Message structure
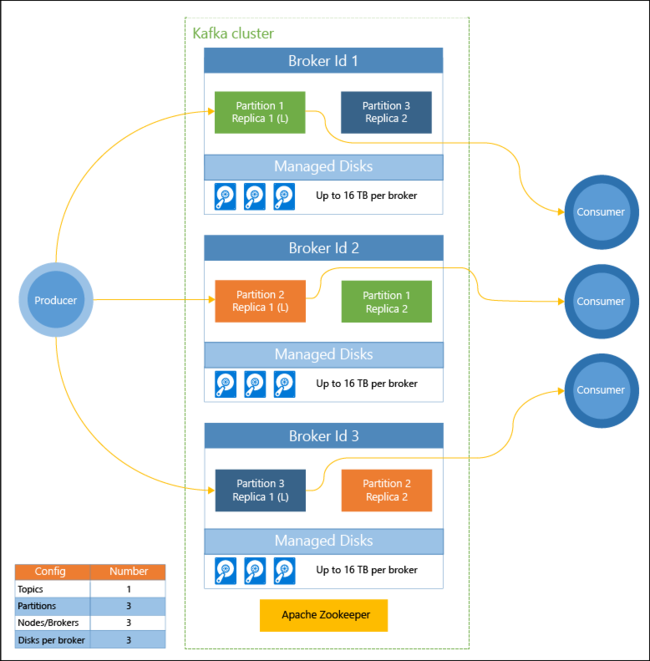
Fundamental data flow

Kafka in Azure through HDinsight
Reference
Apache Kafka official website. https://kafka.apache.org/intro.
Kafka in a Nutshell. https://sookocheff.com/post/kafka/kafka-in-a-nutshell/
Apache Kafka Series – Learn Apache Kafka for Beginners v2, https://tpl.udemy.com/course/apache-kafka/learn/lecture/11566878?start=180#overview
What is Apache Kafka in Azure HDInsight, https://docs.microsoft.com/en-us/azure/hdinsight/kafka/apache-kafka-introduction
Leave a Reply